
티스토리 뷰
1. 데이터 분석 과정

2. EDA vs FE
Garbage in, garbage out
→ EDA & FE의 중요성 : 데이터를 잘 정제해야 좋은 결과를 얻을 수 있다.
- EDA (Exploratory Data Analysis, 탐색적 데이터 분석) : 데이터를 살펴보면서 FE에서 사용할 자료의 특징을 찾는 것
- FE (Feature Engineering) : EDA 단계에서 발견한 자료들의 특징을 이용해 ML/DL의 성능이 잘 나오도록 전처리하는 과정
3. EDA의 4가지 주제
1) 저항성
: 자료의 일부가 파손되었을 때, 영향을 적게 받는 성질
ex. 평균은 중앙값에 비해 자료의 이상치나 입력오류에 큰 영향을 받음 = 중앙값은 평균에 비해 저항성이 큼
2) 잔차의 해석
잔차가 엄청 크거나 작은 값들(=아웃라이어)이 왜 생겼는지를 파악
3) 자료의 재표현
: 데이터의 분석과 해석을 단순하게 할 수 있도록 원래의 변수를 적당한 척도로 바꾸는 것
- 자료가 선형적일 수도 있지만 로그/제곱근/역수 등으로 바꿔야 분석이 단순해질 때도 있음
- 변수를 적당한 척도로 변환하여 분포의 대칭성, 선형성, 분산 안정성 등을 파악해볼 수 있음
4) 그래프를 통한 현시성
: 그래프를 통한 시각화 → 데이터를 직관적 파악
4. EDA 과정
🔆Titanic Dataset : 좌석등급, 성별, 나이 등의 변수들을 가지고 승객의 생존 여부를 예측하는 Task

1) 데이터 형태 파악


2) 변수 타입(Dtype) 파악
- int64 : 정수형 데이터
- float64 : 실수형 데이터
- object : 문자열 데이터
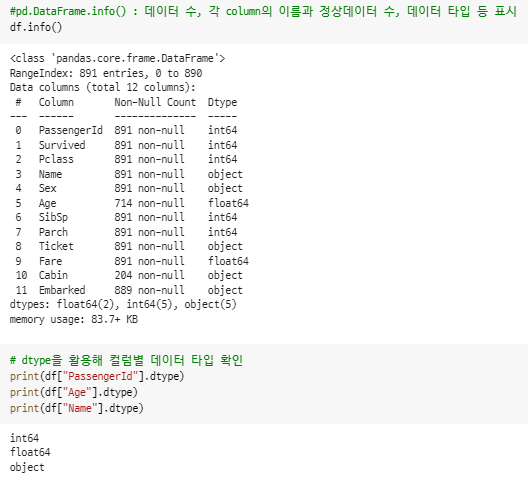

3) 결측치, 이상치 확인
(1) 결측치 (null)


(2) 이상치 (튀는 값)

① .describe()통해 기초 데이터 요약
평균(mean)이 32인데, 중앙값(50%)이 14
→ 이상치 존재 예측 가능

② sns.boxplot 통해 시각화
→ 이상치 확인 가능
4) 종속변수의 분포 확인
[Kaggle] Titanic Dataset으로 survived를 예측하는 Task
- 종속변수 : survived(살아 있으면 1, 아니면 0)
- 독립변수 : 다른 값들

5) 각 변수의 분포 & 변수-종속변수 간 관계 파악
(1) Pclass (자리 등급) : 1/2/3, int64 data
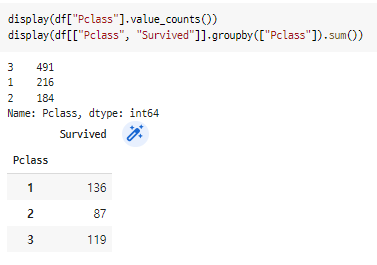
f,ax = plt.subplots(1,2)
df["Pclass"].value_counts().plot(kind = "bar", ax = ax[0]) # bar plot
sns.countplot(x = "Pclass", hue = "Survived", data = df, ax = ax[1]) # count plot
sns.pointplot(x = "Pclass", y = "Survived", data = df) # point plot
sns.violinplot(x = "Pclass", y = "Survived", data = df) # violin plot
(2) Sex (성별) : male/female, object data

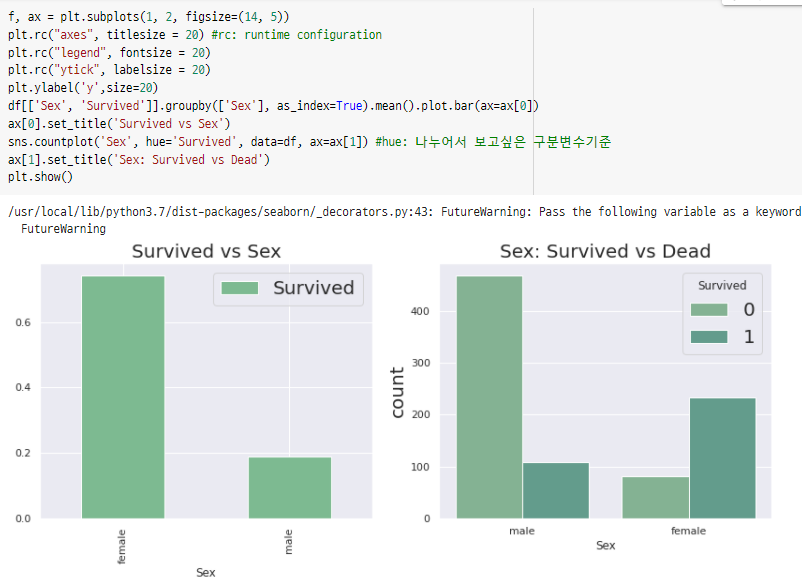
+) 두 독립변수(Pclass, Sex)에 따른 종속변수 분포 동시 확인 가능

(3) Age (나이) : float64 data
→ KDE Plot(확률 밀도 함수)로 표현 가능




(4) Embarked (승선항): S/C/Q, object data

🔆 변수들 간의 관계를 한 눈에 보기 좋은 그래프 : pairplot, heatmap


'Data > Analytics' 카테고리의 다른 글
| [DA] WordCloud (0) | 2022.02.10 |
|---|---|
| [DA] NLP Pipeline - NLTK & KoNLPy (0) | 2022.02.09 |
| [DA] FE (Feature Engineering) (0) | 2022.01.18 |
| [DA] Numpy & Pandas (0) | 2022.01.13 |