
티스토리 뷰

1. ML 문제 해결 과정
문제 정의 : Metric
👇
Preprocessing : FE, 통계적 방법론, 도메인 지식
👇
Modeling : (방법별) 트리, 회귀, 신경망, 클러스터링 / (목적별) 예측, 추천, NLP, CV
2. FE의 중요성
모델링면의 부족한 점은 FE를 통해 보완할 수 있음 (좋은 feature 형성!)
3. 전처리 과정
Brainstorm : 데이터 많이 보기, 다른 문제들 참고
FE : 4가지 방법 + 센스 = 경험의 영역!
Select : Importance 등 참고
Evaluate & Revise : FE가 적용된 새 데이터에 대한 모델의 정확도
4. FE 과정
1) Imputing
- WHY ? 모델한테 Null 값 넣으면 X
- NaN(결측값)을 추정값으로 대체하는 것
- 5% 이상이면, Feature로 추가 (우연이 아님)
▪ Numerical : 0 or median
▪ Categorical : mode, 없다면 'Null'
▪ Random Sampling : 임의로 뽑은 값





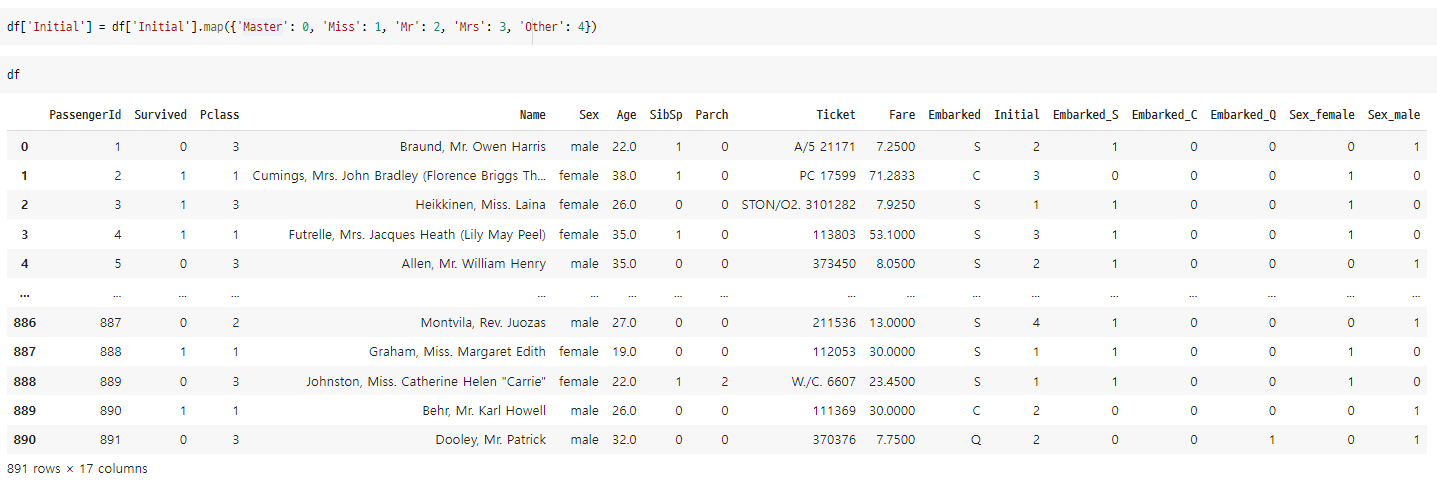
2) Encoding
- WHY ? 모델한테 Categorical 넣으면 X
▪ Categorical 하면 One-hot Encoding (0,1)
▪ 순서가 있다면, Label Encoding 가능 (0,1,2,...)



3) Outlier removing
- WHY ? 모델의 오버피팅 방지
▪ Boxplot 그리고 IQR 밖의 인스턴스 제거

4) Correlation removing
- WHY ? 모델의 오버피팅 방지
- 0.9 넘으면, Feature 제거 추천
- 회귀의 경우 필수 (다중공선성은 회귀의 가정 위반)
다중공선성(Multicollinearity) : 독립변수들 간에 강한 상관관계를 보이는 것

5) FE 결과

+) Feature split
ex. 이름과 성 / 제목과 연도 / 주간의 이름(1주, 2주 등) 주말인지 아닌지, 공휴일인지 아닌지
+) 도메인 지식
ex. 금융데이터라면, 갑자기 주식 price가 (-) 뜨면 무조건 잘못된 데이터라고 판단 가능
'Data > Analytics' 카테고리의 다른 글
| [DA] WordCloud (0) | 2022.02.10 |
|---|---|
| [DA] NLP Pipeline - NLTK & KoNLPy (0) | 2022.02.09 |
| [DA] EDA & 시각화 (0) | 2022.01.17 |
| [DA] Numpy & Pandas (0) | 2022.01.13 |