
티스토리 뷰
1. Machine Learning 개요
1) 정의
(1) ML : 인공지능의 연구 분야 중 하나로, 인간의 학습 능력과 같은 기능을 컴퓨터에서 실현하고자 하는 기술 및 기법
(2) AI ⊃ ML ⊃ ANN ⊃ DL
- AI : 사람이 해야 할 일을 기계가 대신할 수 있는 모든 자동화에 해당
- ML : 명시적으로 규칙을 프로그래밍하지 않고 데이터로부터 의사결정을 위한 패턴을 기계가 스스로 학습
- DL : 인공신경망(ANN) 기반의 모델로, 비정형 데이터로부터 특징 추출 및 판단까지 기계가 한 번에 수행
(3) ML은 경험(E)을 통해 특정한 작업(T)에 대한 성능(P)를 스스로 향상

2) 머신러닝 유형
(1) 지도학습 : 정답이 정해진 문제에 대해 학습. ex) 분류, 예측
문제의 정답을 모두 알려주고 학습시킴
(2) 비지도학습 : 정답이 정해지지 않은 문제에 대해 학습. ex) 군집화, 연관규칙
답을 가르쳐주지 않고 학습시킴
(3) 강화학습 : 보상을 통해 스스로 문제 해결 방법을 학습. ex) 알파고 바둑
보상을 통해 상은 최대화, 벌은 최소화하는 방향으로 행위를 강화하는 학습
3) 전통적 통계분석 방법 VS 머신러닝
(1) 전통적 통계분석 방법
- 목적 : 정해진 분포나 가정을 통해 실패 확률을 줄이는 것
- 모형의 복잡성보다 단순성을 추구하며 신뢰도를 중요하게 생각
- 파라미터의 해석 가능성 또한 중요하게 다룸
ex) 키가 1cm 증가하였을 때 몸무게의 변화량 (선형회귀)
(2) 머신러닝
- 목적 : 모델의 예측 성능을 높이는 것
- 모델의 신뢰도나 정교한 가정(assumption)은 상대적으로 중요도가 낮음
- 오버피팅을 어느 정도 감안하더라도 여러 인자를 사용해 예측 수행
🡪 사용 가능 인자를 모두 넣고 좋은 결과 뽑으면 best (but 오버피팅 번번히 발생)
- 해당 인자가 왜 중요한지는 크게 중요하지 않음
∴ Validation Set을 사용해 Overfitting 방지

4) Validation Set
(1) 전체 Dataset을 Train set / Test set 으로 Split
(2) Train set으로 모델 학습
(3) Test set의 실제 값과 모델이 Test set의 feature들로부터 Predict 한 값을 비교해 모델 성능 평가

ML 모델은 예측 성능을 높이고자 복잡성을 높일 경우 Train set에 Overfitting 되어 Test set에는 낮은 성능이 나올 수 있음
Overfitting 막기 위해 Train set에서 일부분을 Validation set으로 사용

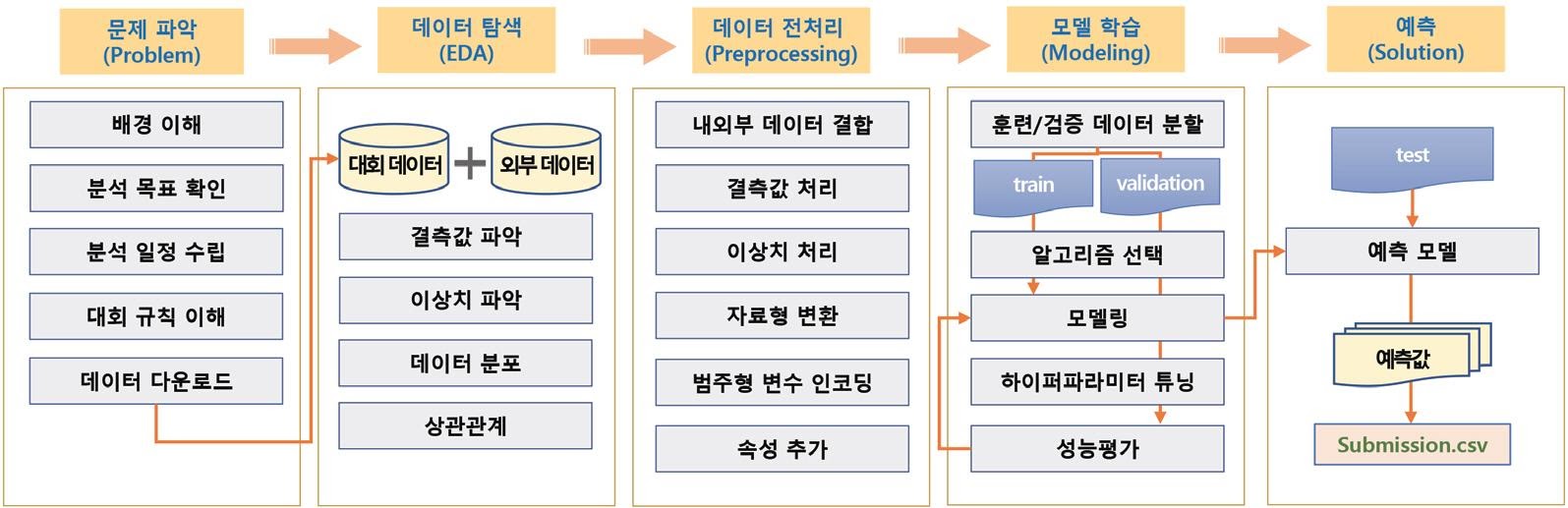
5) 지도학습 과정

2. 분류(Classification)
1) 데이터 타입
- Quantitative (정량적) = Continuous : 숫자로 표시되는 연속적인 값 ex) 가격, 성적 → 회귀
- Qualitative (정성적) = Categorical : 카테고리(Class)로 표시되는 값 ex) 지역, 학과 → 분류
- 숫자로 되어 있다고 모두 정량적 변수인 것은 X ex) 지역 번호
2) 분류 성능 평가
[ Confusion Matrix ]

True Positive(TP) : 실제 True 🡪 예측 True (정답)
True Negative(TN) : 실제 False 🡪 예측 False (정답)
False Positive(FP) : 실제 False 🡪 예측 True (오답)
False Negative(FN) : 실제 True 🡪 예측 False (오답)
(1) Accuracy (정확도)

분류 모델의 성능 지표를 볼 때 정확도만 확인하면 X (Accuracy Paradox)

ex) 암 환자의 비율은 매우 낮기에 모두 암 환자가 아니라고 예측할 경우 정확도는 95%로 높지만 좋은 모델 X
🡪 비대칭(imbalanced) 데이터의 경우 다른 지표들도 살펴봐야 함
(2) Precision (정밀도) : 모델이 True로 분류한 것 중 실제 True 비율

(3) Recall (재현율) : 실제 True인 것 중에서 모델이 True로 예측한 비율

결정 임계값(Decision Threshold)에 따라, Precision과 Recall은 Trade-off 관계
ex) 모든 메일을 스팸메일로 분류하면 실제 스팸메일 중 모두를 잡지만(높은 재현율),
스팸메일로 예측 한 것 중 실제 스팸메일 비율은 낮아짐(낮은 정밀도)
🡪 해결하려는 Task의 목적 & Dataset의 특성에 따라 적절한 성능 평가 지표를 사용해야 함
(4) F1-score : Recall과 Precision의 조화평균 (두 지표 모두 고려 가능)
(산술평균 대신 조화평균 쓰는 이유 : 산술평균보다 값이 작은 값의 비중을 크게 잡기 때문)
🡪 비대칭(imbalanced) 데이터에서 많이 사용되는 좋은 지표


(5) ROC (Receiver Operating Characteristic) curve : FPR과 TPR을 각각 x, y 축으로 놓은 그래프
모든 Threshold에 대한 Binary Classification 성능 (FPR과 TPR의 비율)을 한번에 표시한 그래프

x축 : FPR (False Positive Rate)
: 0인 케이스에 대해 1로 잘못 예측한 비율 (암환자가 아닌데 암이라고 진단)
y축 : TPR (True Positive Rate)
: 1인 케이스에 대해 1로 잘 예측한 비율 (암환자를 진찰해 암이라고 진단)

- Threshold 변화에 따라 ROC curve 위의 점 위치 변화함
가장 왼쪽에 붙으면 : 모든 환자들을 암환자라고 예측 → TPR = 1 = FPR → 우상단
가장 오른쪽에 붙으면 : 모두 암환자가 아니라고 예측 → TPR = 0 = FPR → 좌하단
- 두 그룹을 더 잘 구별할 수 있을수록(멀리 떨어져 있을수록) ROC curve는 좌상단에 붙게 됨
🡪 같은 FPR 일 때 높은 TPR 일수록 좋은 예측 모델
AUC (Area Under Curve) : ROC curve 밑넓이 .. 분류 모델 평가에 자주 쓰이는 성능지표
- AUC = 1 : 두 곡선이 전혀 겹치지 않은 이상적인 분류 모델 (완벽 분류)
- AUC = 0 : 두 곡선이 완전히 겹친, 구분 능력이 없는 최악의 분류 모델
3. 지도학습 모델 종류
1) Linear Model
https://jeonggg119.tistory.com/18?category=1047255
[DS] 통계기초/회귀분석
1. 통계기초 1) ML : 지도학습(회귀, 분류) + 비지도학습(군집화, 변화, 연관) + 강화학습 독립변수, 종속변수가 존재할 때 - 회귀(Regression) : 예측하고 싶은 종속변수가 숫자(수치형 데이터)일 때 사
jeonggg119.tistory.com
2) Support Vector Machine (SVM)
: 결정 경계 (Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델
= 데이터 집합을 가장 잘 분류하는 경계를 찾는 모델 (+ 회귀 Task에서도 사용 가능)
= Margin을 최대화하는 결정 경계를 찾는 모델
Margin (마진)
: Support Vector (결정 경계와 가장 가까운 Train sample) 사이의 거리

이상치(Outlier)를 얼마나 허용할 것인가?
[상] Hard Margin SVM : 이상치를 허용하지 않아 Margin 매우 작은 모델 (Overfitting 문제 가능성)
[하] Soft Margin SVM : 이상치를 포함하도록 기준 잡아 Margin 큰 모델 (but Underfitting 문제 가능성)

3) Decision Tree (의사결정나무)
: 여러 규칙을 순차적으로 적용하면서 독립 변수 공간을 분할하는 분류 모델
= Classification, Regression Task 모두 사용 가능한 지도학습 모델
= 특정 기준에 따라 데이터를 분리하는 모델 (Node : 기준에 따라 분할된 박스)
(1) 장점
- 인간의 의사결정 과정과 비슷해 인과관계 설명 가능 (높은 설명도)
- 범주형 자료를 Input 변수로 사용 가능
- 이상치(Outlier)에 강함 ex) 습도 450 > 70 → Don't play
- 통계적 가정을 크게 요구하지 X
(2) 단점
- Overfitting에 취약 → 앙상블, 가지치기 등으로 방지
- Training data가 조금만 바뀌어도 Tree 모양이 크게 바뀜


(3) Process of DT
① 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 분기 🡪 Information Gain이 높은 방법으로 분기
Information Gain = Entropy(Parent) - [Weighted Average]*Entropy(Children)

[9+, 5-] 의미 : 14명 중, 9명은 운동을 한다(+) & 5명은 운동을 안한다(-)
S : [9+, 5-] 에서 Humidity 기준으로 분류 → Humidity가 높으면 [3+, 4-], 보통이면 [6+, 1-]로 분류됨
S : [9+, 5-] 에서 Wind 기준으로 분류 → Wind가 약하면 [6+, 2-], 강하면 [3+, 3-]로 분류됨
Gain(Humidity) > Gain(Wind) 이므로 Humidity로 나눴을 때 더 잘 분류됨

② 나뉜 각 범주에서 다시 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 분기
③ Termial Node (마지막 분기)가 더 이상 분리되지 않을 때까지 반복
BUT 분기를 지나치게 많이 하면, Train data 대해 Overfitting 발생
🡪 Max Depth 설정해 Overfitting 방지

(4) DT 앙상블 모델
- 여러 개의 Decision Tree를 합친 모델(앙상블 모델) : 성능이 매우 좋음 !
- 합치는 방법에 따라 Bagging, Boosting 등의 방법이 있음 (XGBoost, Light GBM이 대표적)
- Kaggle Competition에서 XGBoost랑, GridSearchCV 많이 사용
+) 대부분의 문제에서 DL보다 쓰기 쉽고, 성능 좋을 수 O