
티스토리 뷰
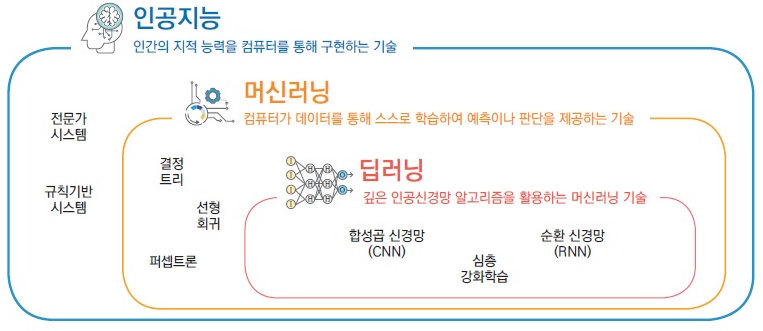
1. AI/ML/DL 개요
1) 포함 관계 및 정의
2) DL 분야
(1) Dataset (데이터셋)
- Training Data
- Validation Data
- Test Data
(2) CV (컴퓨터비전)
- Image Classification
- Object Detection
- Image Segmentation
- Saliency Detection (특정 인식)
(3) NLP (자연어처리)
- Text Classification & Ranking (텍스트 분류 및 순위)
- Sentiment Analysis (감성 분석)
- Doc Summarization (문서 요약)
- Name-Entity Recognition, NER (개체 이름 인식)
- Speech Recognition (음성 인식)
- Machine Translation (기계 번역)
3) NLP
토큰화 (Tokennization)
: NLP에서 크롤링 등으로 얻은 데이터를 전처리 하는 과정
주어진 데이터에서 의미 있는 단어들을 <토큰> 단위로 정규화
from nltk.tokenize import word_tokenize
print(word_tokenize("<문장>"))
from nltk.tokenize import WordPunctTokenizer
print(WordPunctTokenizer().tokenize("<문장>"))
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print(text_to_word_sequence("<문장>"))
불용어 제거 (Stopwords)
: 자주 등장하지만 분석 및 학습에 방해가 되는 단어들을 제거
Ex) I, my, me, over, 조사, 접미사 등
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from konlpy.tag import Okt
example = "Family is not an important thing. It's everything."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example)
result = []
for word in word_tokens:
if word not in stop_words:
result.append(word)
print('불용어 제거 전 :',word_tokens)
>>> ['Family', 'is', 'not', 'an', 'important', 'thing', '.', 'It', "'s", 'everything', '.']
print('불용어 제거 후 :',result)
>>> ['Family', 'important', 'thing', '.', 'It', "'s", 'everything', '.']
패딩 (Padding)
: 길이가 다른 여러 문장과 문서들의 길이를 통일해 한번에 처리할 수 있도록 함
from tensorflow.keras.preprocessing.sequence import pad_sequences
preprocessed_sentences = [['barber', 'person'],
['barber', 'good', 'person'],
['barber', 'huge', 'person'],
['knew', 'secret'],
['secret', 'kept', 'huge', 'secret'],
['huge', 'secret'],
['barber', 'kept', 'word'],
['barber', 'kept', 'word'],
['barber', 'kept', 'secret'],
['keeping', 'keeping', 'huge', 'secret', 'driving', 'barber', 'crazy'],
['barber', 'went', 'huge', 'mountain']]
encoded = tokenizer.texts_to_sequences(preprocessed_sentences)
print(encoded)
>>> array([[ 0, 0, 0, 0, 0, 1, 5],
[ 0, 0, 0, 0, 1, 8, 5],
[ 0, 0, 0, 0, 1, 3, 5],
[ 0, 0, 0, 0, 0, 9, 2],
[ 0, 0, 0, 2, 4, 3, 2],
[ 0, 0, 0, 0, 0, 3, 2],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 6],
[ 0, 0, 0, 0, 1, 4, 2],
[ 7, 7, 3, 2, 10, 1, 11],
[ 0, 0, 0, 1, 12, 3, 13]], dtype=int32)
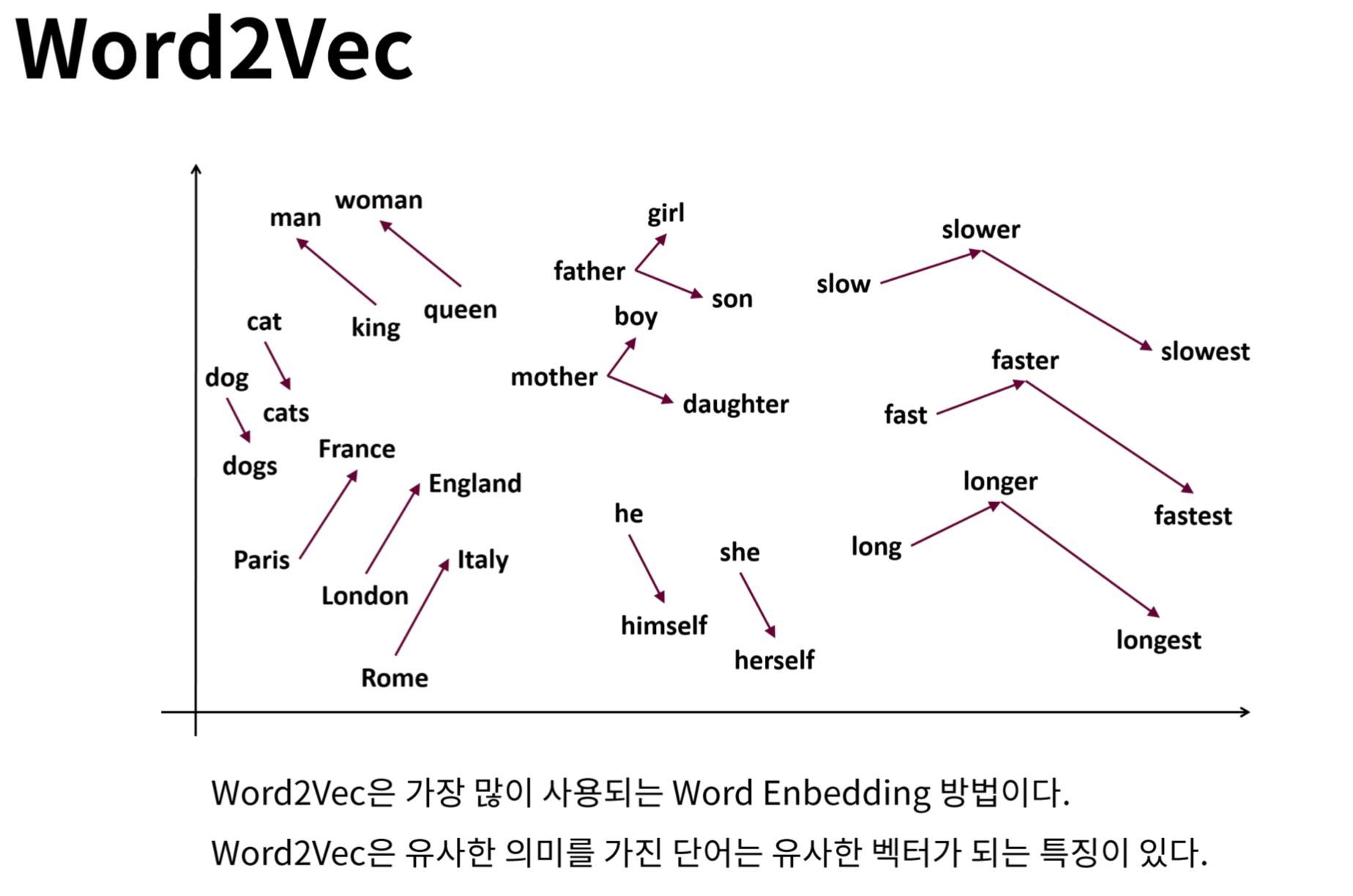
워드 임베딩 (Word Embedding)
: 단어를 벡터로 표현하는 방법
Ex) Word2Vec : 단어 유사도를 수치화
Embedding layer
(1) 등장 배경
One-hot vector의 한계점 : ① 의미적 연산 + ② 확장성 측면에서 한계점을 가짐
① 내적 = 0 → 연산을 통해 두 알파벳 or 단어 or 문장 간의 의미적 차이나 유사도(ex. cosine similarity) 구하는 것 불가능
② 하나의 요소가 추가될 때마다 vector 길이가 늘어남 → 기존 모델이 무의미해짐
(2) Embedding
: 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자형태인 vector로 바꾼 결과 혹은 그 일련의 과정 전체
= 알파벳이나 단어 같은 기본 단위 요소들을 일정한 길이를 가지는 vector 공간에 투영하는 것
ex. Word Embedding : 일정한 크기의 vector에 단어들을 투영하는 방법 (의미적 공통점 가지는 단어끼리 유사한 값)
(3) 역할(기능)
- 단어/문장 간 관련도 계산(Word2Vec) : 단어를 전체 단어들 간의 관계에 맞춰 해당 단어의 특성을 갖는 vector로 변경
- 의미적/문법적 정보 함축 → 단어 vector 간 사칙 연산 가능
- 전이 학습(Transfer learning) : 모델의 성능과 수렴속도가 빠른 임베딩을 다른 딥러닝 모델의 입력값으로 사용 가능
- 특정 도메인에서 임베딩 해두면 비슷한 의미를 가지는 단어들끼리 가까운 곳에 위치하게 되므로 유사 단어 찾기 편리
(4) 대표적인 기법
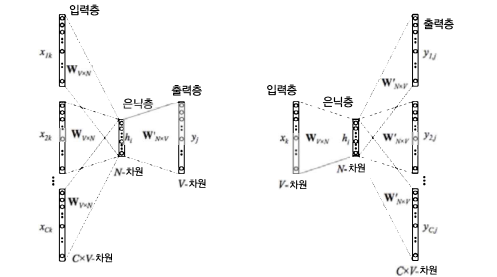
① CBOW (Continuous Bag-Of-Words)
: '주변 단어들'로부터 '가운데 들어갈 단어 하나'가 나오도록 모델을 학습해 임베딩 벡터를 얻는 방식
- 문장 또는 문서의 모든 문장을 이 방식으로 학습하면 문서에서 사용된 단어들이 의미적(semantically)으로 임베딩됨
(ex. 'The quick brown dog jumps over the laxy fox' 에서 'dog'와 'fox'는 vector 공간상 가까운 위치에 임베딩됨)
② skip-gram
: '중심 단어'로부터 '주변 단어들'이 나오도록 모델을 학습해 임베딩 벡터를 얻는 방식
(ex. 'fox'가 들어오면 'quick', 'brown', 'jumps' 등의 단어들이 나오도록 학습됨)
- 학습 과정을 끝낸 후 가중치 행렬의 각 행을 단어 vector로 사용함
- CBOW로 만든 단어 vector 보다 단어 간의 유사도를 잘 측정하며 복잡한 특징도 잘 잡아냄 (일반적으로 성능 더 좋음)
(5) Embedding 함수를 이용한 LSTM, GRU 모델 구현
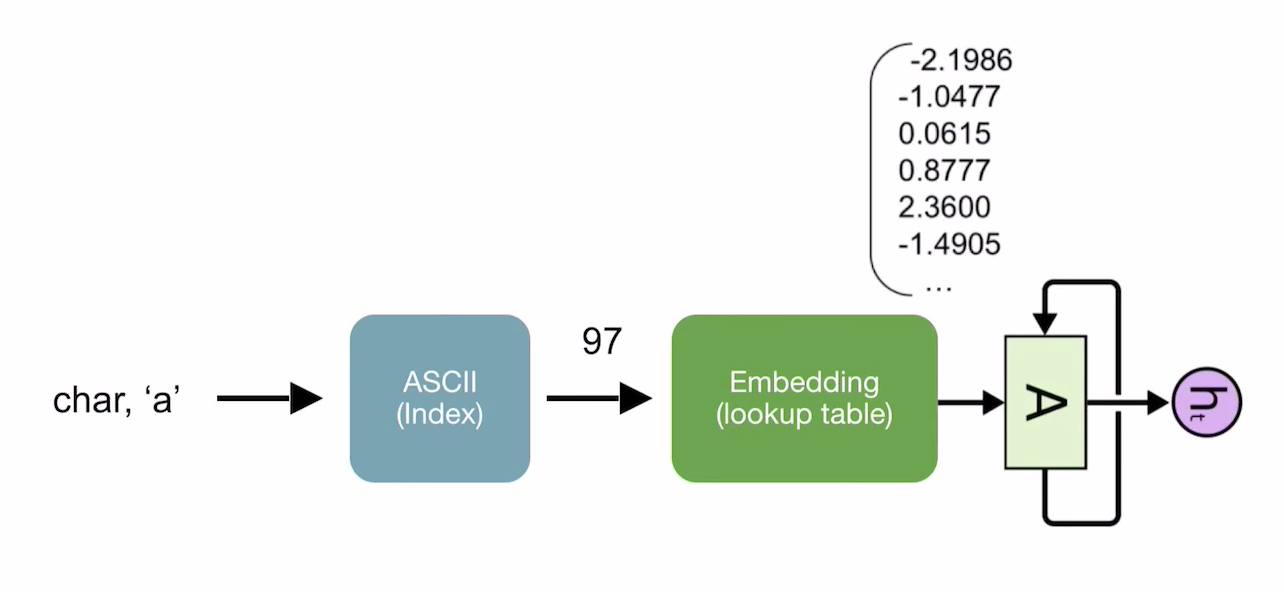
torch.nn.Embedding class 이용해서 Embedding instance 생성
→ 문자가 입력으로 들어오면 먼저 문자 사전(ASCII)에 의해 Index로 변환됨
→ 이 Index를 Embedding instance에 전달하면 vector가 결과로 나옴
→ 이 vector를 가지고 RNN, LSTM, GRU를 통해 모델을 학습시킴 !
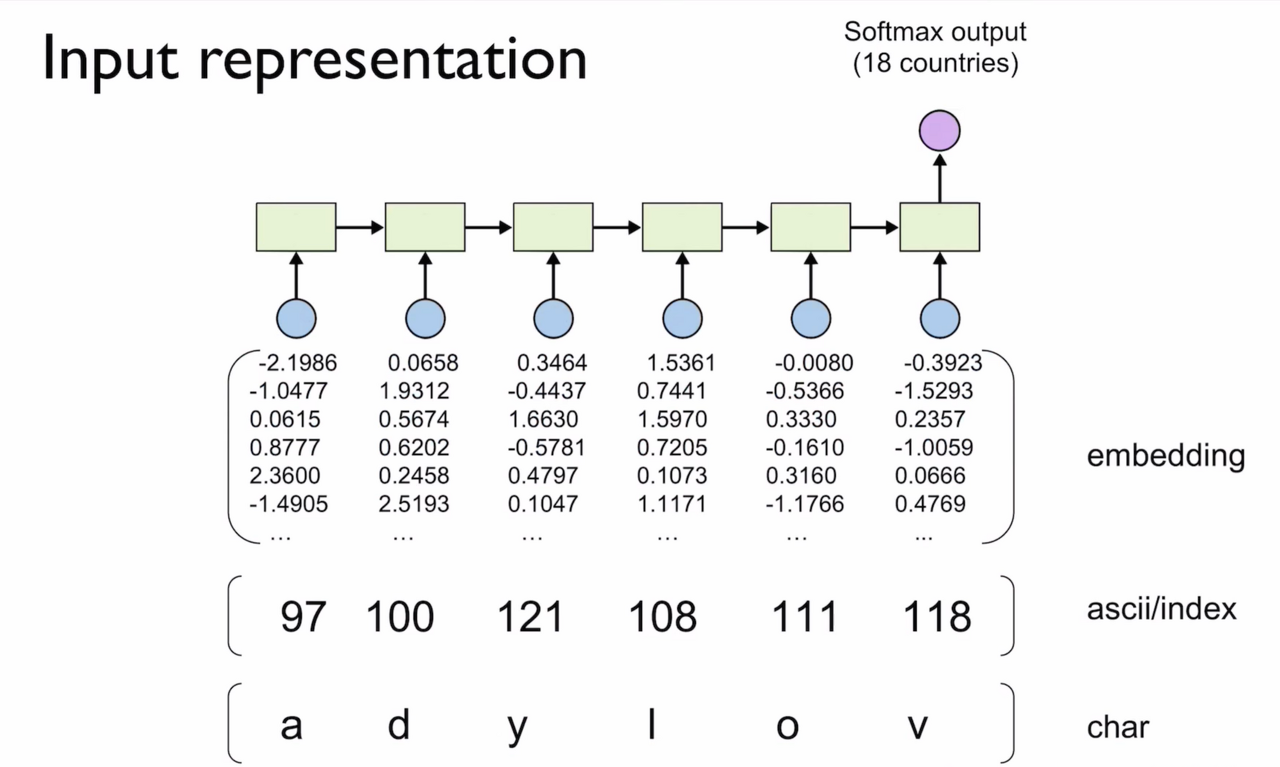
순환 신경망 (RNN)
: NLP에서 단어의 시퀀스인 문장들을 처리하기 위한 가장 기본적 인공 신경망 시퀀스 모델
NLP 활용 사례
: 연관검색어, 이모티콘 플러스, SIRI, 번역기, 오타 교정 등
2. RNN (Recurrent Neural Network)
1) 정의 및 특징
RNN : 입력과 출력을 '시퀀스' 단위로 출력하는 모델 (기존 DNN은 시퀀스 처리 불가했음)
시퀀스(sequence) 데이터 : 순서가 존재하는 데이터 (ex. 언어)
시계열(time series) 데이터 : 순서가 존재하며 시간에 따른 의미도 존재하는 데이터 (ex. 주가)
- RNN은 시계열 데이터(자연어처리, 센서데이터, 주식데이터 등) 처리에 용이
- 언어는 시퀀스 데이터이기에 대부분의 NLP 모델은 RNN 기반
Ex) '나는 너를 좋아한다.' 의 뜻 풀이 : '나는' → '너를' → '좋아한다' 순서로 문장 이해 가능
- RNN이라고 이미지를 사용하면 안 되는 것은 X
이미지, 자연어 모두 결국 다 숫자로 이루어져 있기에
이미지에 RNN 적용 or 자연어에 CNN 적용 가능 (다만, 좀 더 특화된 부분이 있을 뿐)
2) 구조 및 연산
(1) RNN 구조
- 각 시점마다 입력벡터(x_t), 출력벡터(o_t), 은닉층(h_t)으로 구성 (각 시점마다 신경망 존재)
- 은닉층(h_t)에는 'Memery cell'이 존재해 결과값을 다음 은닉층(h_t+1)에 넘겨줌
= 현재 셀에서 이전 셀의 값을 받아 현재 셀의 상태를 규정
- 이전 가중치를 가지고 다음 가중치를 계산할 때 참고하기에 시퀀스 데이터에 특화됨


① 현재 시점의 입력값 x_t와
② 이전 시점의 Hidden state h_t-1을 Input으로 받아
③ 현재 시점의 Hidden state h_t 계산
④ h_t를 바탕으로 현재 시점의 출력 y_t(o_t) 계산
⑤ 현재 시점의 Hidden state는 다음 시점의 Input
(2) RNN 연산 (벡터와 행렬의 연산)
각 시점별 은닉층 연산
h_t = tanh(W_hh * h_t-1 + W_xh * x_t + b_h)
d : 단어 벡터 x 의 차원(크기)
D_h : Hidden state h 의 크기

Activation function : 주로 tanh (-1~1 값) 사용 (Gradient를 최대한 오래 유지하기 위함)
은닉층(h)이나 시점(t)이 너무 많으면 Gradient가 Vanishing 되거나 너무 커질 수 있음
* ReLU (0~x 값) 사용하지 않는 이유? : 0일 경우 바로 사라지거나 x가 클 경우 발산할 수 있음
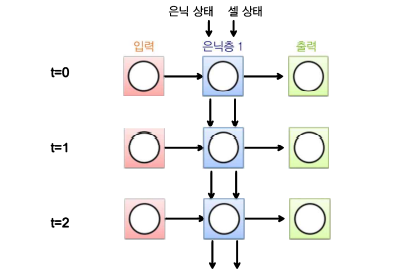
(3) RNN 전체 작동원리
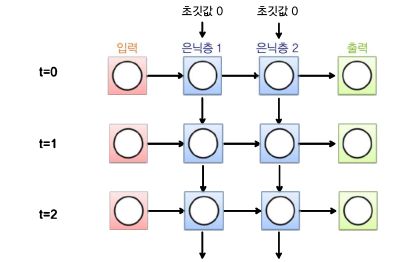
은닉층의 node들은 어떤 초기값을 가지고 계산이 시작되며,
t=0시점에서 입력값 + 각 node 초기값의 조합으로 t=0일 때 은닉층의 값들이 계산되어 결과값(출력값)이 도출됨
t=1시점에서 입력값 + t=0시점에서 계산된 은닉층 값들의 조합으로 t=1일 때 은닉층의 값과 결과값이 다시 계산됨
이러한 과정이 지정한 시간만큼 반복됨
RNN은 계산에 사용된 '시점의 수'에 영향을 받음
Ex. t=0 ~ t=2 까지 계산에 사용됐다면 그 시간 전체에 대한 backprop 해야 함
→ 시간에 따른 역전파 Backpropagation through time (BPTT)

t=2시점의 loss를 backprop 하려면?
- loss를 입력과 은닉층들 사이의 가중치로 미분해 loss에 대한 각각의 비중을 구해 update
그 과정에서 은닉층의 이전 시점의 값들(=가중치 + 입력값 + 이전 시점의 값들)이 연산에 포함됨
- RNN은 각 위치별로 같은 가중치를 공유하므로 t=0시점의 node값들에도 영향을 줘야 함
시간을 역으로 거슬러 올라가는 방식으로 각 가중치를 update = BPTT
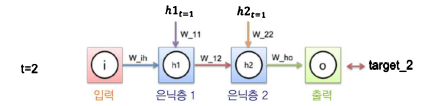
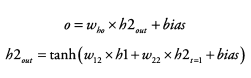
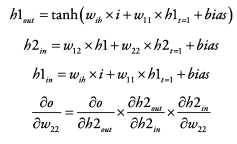
t=2시점에서 발생한 loss는 t=2, 1, 0시점에 전부 영향을 줌
t=1시점에서 발생한 loss는 t=1, 0 시점에 영향을 줌
t=0시점의 loss는 t=0의 가중치에 영향을 줌
실제 update할 때는 가중치에 대해 시점별 기울기를 다 더하여 한 번에 update 진행
3) 예시
RNN의 입력과 출력의 길이(개수)를 다르게 설정해 다양한 용도로 사용 가능
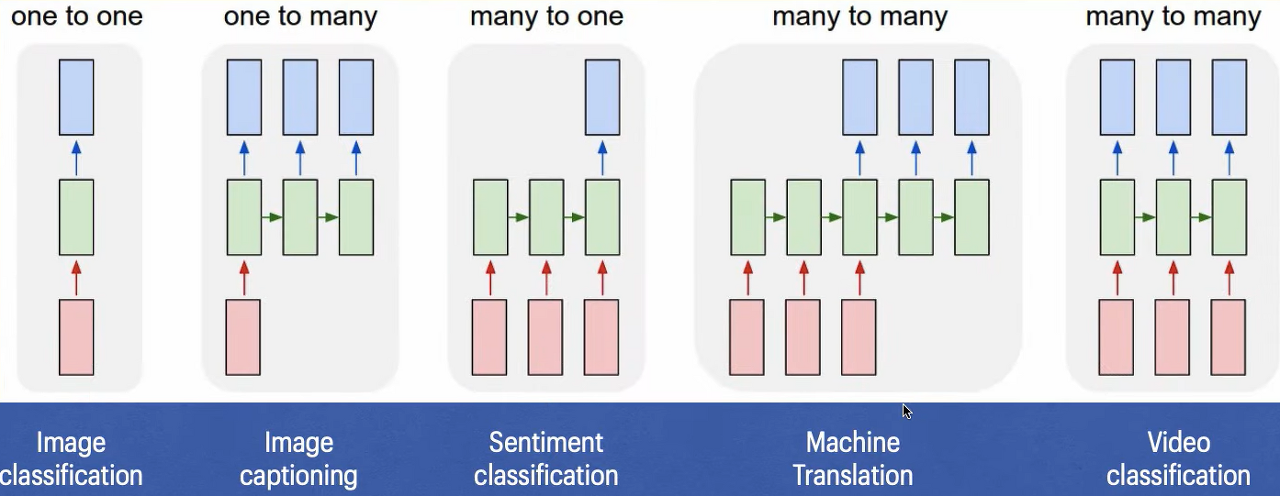

(1) 일대다 (one to many)
Ex. 이미지에 대한 캡션 출력 (Image captioning)
이미지 : 픽셀을 하나의 행렬로 표현 가능
캡션 : 각 단어가 벡터이기에 단어 여러 개로 이루어진 문장은 시퀀스
(2) 다대일 (many to one)
Ex. 스팸 메일 분류 / 감정 분류 (Sentiment classification)
메일에 있는 여러 단어들을 기반으로 스팸인지 아닌지를 판단
(3) 다대다 (many to many)
Ex. 개체명 인식 / 번역 (Machine translation)
단어는 그 주변에 있는 단어에 따라 뜻이 달라지기에 RNN으로 분류해야 정확함
4) 한계
(1) Vanishing Gradient Problem
RNN은 관련 정보와 그 정보를 사용하는 지점 사이의 거리가 멀수록 (=타임 시퀀스가 길수록, 긴 문장일수록)
Backprop 시 tanh의 미분값(0~1사이의 값)이 여러 번 곱해지며 Gradient가 점차 줄어들어 학습 제대로 X

(2) 장기 의존성 문제 (The Problem of Long-Term Dependencies)
비교적 짧은 시퀀스에 대해서만 효과를 보이는 문제
Time step이 길어질수록 정보량 소실 증가
3. Advanced RNN 기반 신경망
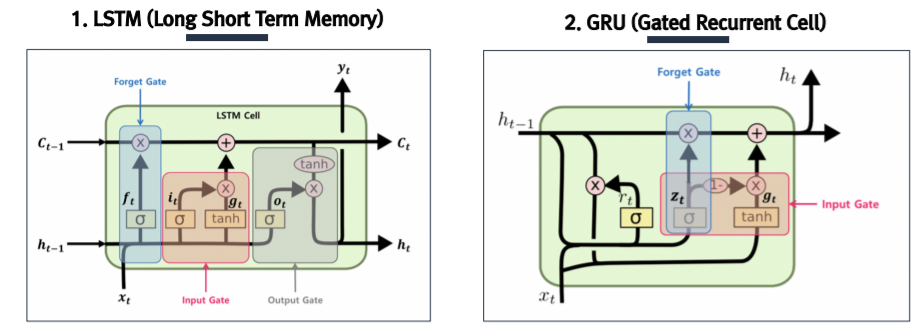
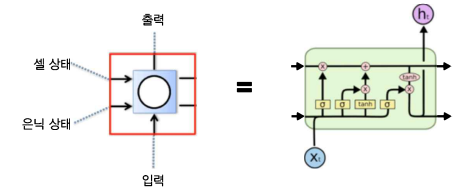
1) LSTM (Long Short Term Memory)
은닉층(Memory Cell)에 Input Gate, Output Gate, Forget Gate를 이용해 불필요한 정보를 삭제해 넘겨줌
→ Vanishing Gradient Problem 어느 정도 해결
LSTM : 기존의 RNN 모델에 장기기억을 담당하는 Cell State 부분을 추가한 모델
남길 건 남기고, 잊을 건 잊고, 새로 추가할 건 추가해서 Cell State에는 중요한 정보만 계속 흘러가도록! by using Gates
각 time step의 output이라고 할 수 있는 Hidden State는 Cell State를 적당히 가공해서 내보냄
Gate = g_t = sigmoid(W_g * V_input) : 0~1 사이 값을 갖는 elements로 구성된 vector
C_(t-1) * G : element-wise coefficient multiplication → 각 dimension의 정보를 pass할지 block할지 조절!

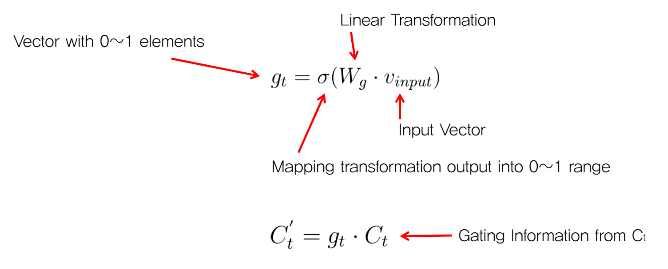
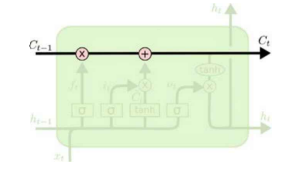
Cell State (셀 상태)
: 장기기억을 담당하는 부분
- 곱하기(X) 부분 : 기존 정보를 얼마나 남길 것인지에 따라 비중을 곱하는 부분
- 더하기(+) 부분 : 현재 들어온 데이터와 기존의 Hidden State를 통해 정보를 추가하는 부분
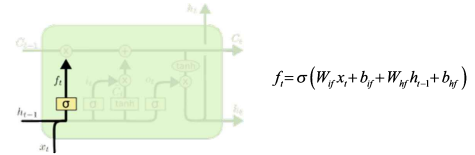
Forget Gate (망각 게이트)
: 기존의 정보들로 구성되어 있는 Cell State의 값을 얼마나 잊어버릴 것인지 비중을 정하는 부분
= 현재 시점에서의 입력값 x_t + 직전 시점의 Hidden State 값 h_(t-1)을 입력으로 받아서,
→ 각 입력에 가중치 w를 곱해주고 편차 b를 더한 값을 sigmoid 함수에 넣어 0~1 사이의 값을 출력
1️⃣ f_t 를 통해 C_(t-1)에서 불필요한 정보를 지움
Input Gate (입력 게이트)
: 어떤 정보를 얼만큼 Cell State에 새로 저장할 것인지 정하는 부분
새로운 입력값 x_t과 직전 시점의 Hidden State 값 h_(t-1)을 입력으로 받아서,
- sigmoid 함수 통과 : 0~1 사이의 값 출력 → 새롭게 추가할 정보를 얼만큼의 비중으로 Cell State에 더해줄지 정함
- tanh 통과 : -1~1 사이의 값 출력 → 새롭게 Cell State에 정보 추가 (임시 Cell State 값)
2️⃣ C_(t-1)에 새로운 입력값 x_t와 h_(t-1)을 보고 중요한 정보를 입력함 & 임시 ~C_t를 계산
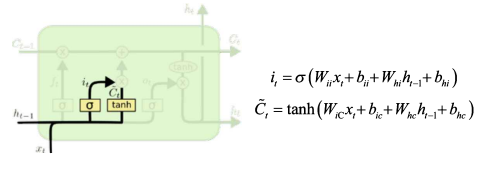
① Cell State UPDATE
현재 시점의 새로운 입력값 + 직전 시점의 Hidden State 값의 조합으로
기존 Cell State 정보 C_(t-1)를 얼만큼 forget하고 전달할지
& 어떤 정보 ~C_t를 얼만큼의 비중으로 더할지 정함
3️⃣ 위 두 과정을 통해 C_t 만듦 (update) : f_t로 C_(t-1)의 불필요한 정보를 날리고, 임시 C_t 정보를 추가
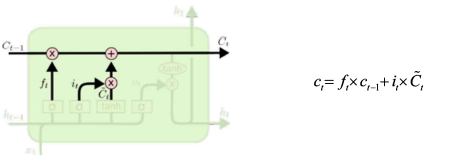
② Hidden State UPDATE
Sigmoid 비중을 정하는 부분은 앞단과 동일
새로운 Hidden State는 UPDATE된 Cell State 값을 tanh에 통과시킨 -1~1 사이의 비중을 곱한 값으로 생성됨
4️⃣ C_t를 적절히 가공해 해당 t에서의 h_t를 만듦 (update) : C_t를 가공할 output gate o_t로 h_t 계산
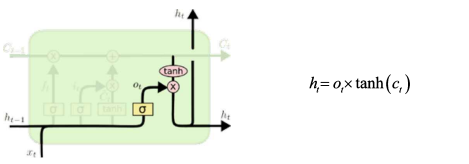
5️⃣ C_t와 h_t를 next step인 t+1로 전달
Q) LSTM은 어떻게 Vanishing Gradient 문제 해결 ?
: t시점에서 Cell State에 기록된 정보가 지워지지 않고 t+n에서 활용되었을 때,
중간에 Nonlinear act function 거치지 않고 흐른 것이기에 Vanishing Gradient 문제 일부 해소 가능!
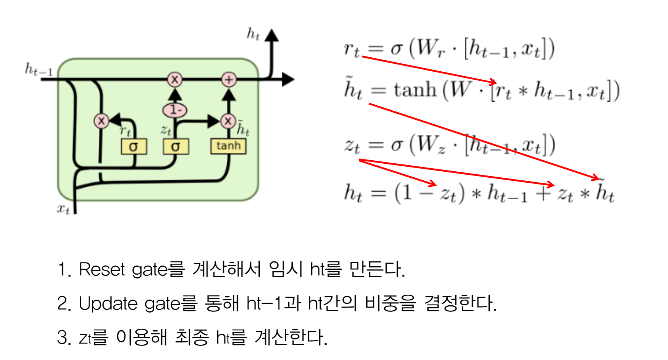
2) GRU (Gated Recurrent Cell)
LSTM을 간소화한 신경망으로 Update Gate, Reset Gate 총 2가지를 활용
→ Vanishing Gradient Problem 어느 정도 해결
- LSTM보다 간단한 구조이지만 성능 면에서 밀리지 않는 모델
- LSTM과 달리 Cell State와 Hidden State를 분리하지 않고, Hidden State 하나로 합침
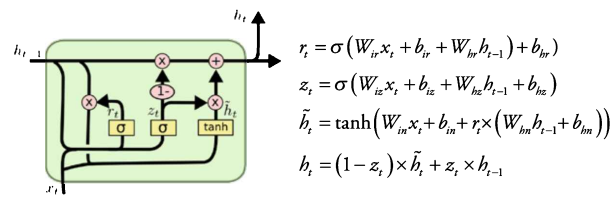
① Update gate (z_t)
: 현 시점의 새 입력값 x_t와 직전 시점의 Hidden State 값 h_(t-1)에 가중치 곱하고 sigmoid 통과시켜 update 비중 정함
② Reset gate (r_t)
: Update gate와 동일한 입력, sigmoid 통과시켜 ~h_t 구할 때 기존 Hidden State를 얼만큼 반영할지에 대한 비중 정함
→ ~h_t : 기존 Hidden State h_(t-1)에 가중치가 곱해진 값 + 새로운 입력값 x_t에 가중치 곱한 값을 tanh 통과시켜 구함
③ 새로운 Hidden State (h_t)
: 앞서 구한 가중치로 기존 Hidden State h_(t-1)과 ~h_t의 가중 합을 곱해 새로운 Hidden State 값 h_t 구함
Simple (Vanilla) RNN과 비교

한 시점의 은닉층(Memory Cell)로 표현을 하자면 RNN은 LSTM, GRU에 비해 굉장히 단순한 구조
하지만 기본적으로 시퀀스를 처리하기 위한 메커니즘은 동일 + 셋 다 상황에 맞게 사용됨
- Simple RNN : 빠르지만 짧은 시퀀스에만 사용 가능
- LSTM : 느리지만 많은 양의 데이터 / 긴 시퀀스에 용이
- GRU : 중간 (LSTM보다 간단한 구조이지만 성능 밀리지 않음)
4. 코드 실습
1) Text Generation using RNN : Sentences
(1) Data Preprocessing
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
from tensorflow.keras.utils import to_categorical
# (1) 예제 문장 저장
text = """경마장에 있는 말이 뛰고 있다\n그의 말이 법이다\n가는 말이 고와야 오는 말이 곱다\n"""
t= Tokenizer()
t.fit_on_texts([text])
vocab_size = len(t.word_index) + 1
# 케라스 토크나이저의 정수 인코딩은 인덱스가 1부터 시작하지만,
# 케라스 원-핫 인코딩에서 배열의 인덱스가 0부터 시작하기 때문에
# 배열의 크기를 실제 단어 집합의 크기보다 +1로 생성해야함
# (2) 훈련 데이터 만들기
sequences = []
for line in text.split('\n'): # \n 기준으로 문장 토큰화
encoded = t.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1] # 길이가 2 이상인 gram들 저장
sequences.append(sequence)
# 가장 긴 샘플의 길이에 전체 샘플 길이 맞추기 (6으로 패딩)
max_len = max(len(l) for l in sequences)
sequences = pad_sequences(sequences, maxlen = max_len, padding='pre')
# 각 샘플의 마지막 단어 레이블로 분리하기
sequences = np.array(sequences)
X = sequences[:,:-1] # 각 리스트의 마지막 값을 제외하고 저장
y = sequences[:,-1] # 각 리스트의 마지막 값만 저장
# 레이블에 대해 one-hot encoding
y = to_categorical(y, num_classes = vocab_size
(2) Simple RNN Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, SimpleRNN
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length = max_len-1))
# 각 단어를 10차원으로 embedding, 레이블 분리 후 길이는 -1
model.add(SimpleRNN(32)) # 은닉 상태 크기
model.add(Dense(vocab_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X,y,epochs = 200, verbose=2)
(3) Result
# 문장 생성 함수
def sentence_generation(model, t, current_word, n):
init_word = current_word
sentence = ''
for _ in range(n):
encoded = t.texts_to_sequences([current_word])[0] # 현재 단어 정수 인코딩
encoded = pad_sequences([encoded], maxlen = 5, padding = 'pre') # 패딩
predict_x=model.predict(encoded, verbose=0)
classes_x=np.argmax(predict_x,axis=1) # 입력한 현재 단어 x 에 대해 다음 단어 예측, result에 저장
for word, index in t.word_index.items():
if index == classes_x:
break
current_word = current_word + ' ' + word # 예측 단어를 현재 단어로 변경
sentence = sentence + ' ' + word # 문장에 예측 단어를 추가하여 저장
sentence = init_word + sentence
return sentence
print(sentence_generation(model, t, '경마장에', 4))
print(sentence_generation(model, t, '그의', 2))
print(sentence_generation(model, t, '가는', 3))
2) Text Generation using RNN : Articles
(1) Data Preprocessing
import pandas as pd
from string import punctuation
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
from tensorflow.keras.utils import to_categorical
df = pd.read_csv('/content/drive/MyDrive/Ybigta/RNN/ArticlesApril2018.csv')
print('Number of columns: ', len(df.columns))
print(df.columns)
# 모든 기사의 제목 하나의 리스트로 저장
headline = []
headline.extend(list(df.headline.values))
headline[:10]
# headline 중 unknown 처리
print('총 샘플의 개수 : {}'.format(len(headline))) # 현재 샘플의 개수
headline = [n for n in headline if n != "Unknown"] # Unknown 값을 가진 샘플 제거
print('노이즈값 제거 후 샘플의 개수 : {}'.format(len(headline))) # 제거 후 샘플의 개수
headline[:10]import re
# 데이터 전처리: 구두점 제거, lowercase()
def data_preprocessing(text):
text = re.sub(r'[^\w\s]','',text)
text = text.lower()
return text
cnt=0
for i in headline:
headline[cnt] = data_preprocessing(i)
cnt+=1
headline[:10]
# 토큰화 및 단어 집합 크기 확인
t= Tokenizer()
t.fit_on_texts(headline)
vocab_size = len(t.word_index) + 1
print('단어 집합의 크기: {}'.format(vocab_size))
# 정수 인코딩 & 하나의 문장을 2 이상 길이의 훈련 데이터로 만들기"
sequences = []
for text in headline:
for line in text.split('\n'): # \n 기준으로 문장 토큰화
encoded = t.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1] # 길이가 2 이상인 gram들 저장
sequences.append(sequence)
# 가장 긴 샘플의 길이에 전체 샘플 길이 맞추기 (max_len으로 패딩)
max_len = max(len(l) for l in sequences)
sequences = pad_sequences(sequences, maxlen=max_len, padding='pre')
# 훈련 데이터에서 레이블 분리 (각 문장의 마지막 단어만 분리해서 y로)
sequences = np.array(sequences)
X = sequences[:,:-1]
y = sequences[:,-1]
# 레이블에 대한 one-hot encoding
y = to_categorical(y, num_classes = vocab_size)
(2) Simple RNN Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, SimpleRNN
model = Sequential()
model.add(Embedding(vocab_size, 32, input_length = max_len-1))
# 각 단어를 32차원으로 embedding, 레이블 분리 후 길이는 -1
model.add(SimpleRNN(32))
model.add(Dense(vocab_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X,y,epochs = 300, verbose=2)
(3) Result
# 문장 생성 함수
def sentence_generation(model, t, current_word, n): # 모델, 토크나이저, 현재 단어, 반복할 횟수
init_word = current_word # 처음 들어온 단어도 마지막에 같이 출력하기 위해 저장
sentence = ''
for _ in range(n): # n번 반복
encoded = t.texts_to_sequences([current_word])[0] # 현재 단어에 대한 정수 인코딩
encoded = pad_sequences([encoded], maxlen=max_len-1, padding='pre') # 데이터에 대한 패딩
predict_x=model.predict(encoded, verbose=2)
classes_x=np.argmax(predict_x,axis=1)
# 입력한 X(현재 단어)에 대해서 Y를 예측하고 Y(예측한 단어)를 result에 저장.
for word, index in t.word_index.items():
if index == classes_x: # 만약 예측한 단어와 인덱스와 동일한 단어가 있다면
break # 해당 단어가 예측 단어이므로 break
current_word = current_word + ' ' + word # 현재 단어 + ' ' + 예측 단어를 현재 단어로 변경
sentence = sentence + ' ' + word # 예측 단어를 문장에 저장
# for문이므로 이 행동을 다시 반복
sentence = init_word + sentence
return sentence
# Text Generation 결과 확인
# 임의의 단어 'good'에 대해서 10개의 단어를 추가 생성
print(sentence_generation(model, t, 'good', 10))
5. 추가 내용 정리 및 Pytorch 코드
https://jeonggg119.tistory.com/17
[Ch6] 순환신경망(RNN)
6.1 RNN의 발달 과정 RNN : 순서가 있는 데이터에서 의미(패턴, 상관관계, 인과관계 등)를 찾아내기 위해 고안된 모델 시퀀스(sequence) 데이터 : 순서가 존재하는 데이터 (ex. 언어) 시계열(time series) 데
jeonggg119.tistory.com
'Data > Science' 카테고리의 다른 글
| [DS] CNN (0) | 2022.01.29 |
|---|---|
| [DS] MLP (0) | 2022.01.28 |
| [DS] Machine Learning (ML) (0) | 2022.01.26 |
| [DS] 통계기초/회귀분석 (0) | 2022.01.21 |