
티스토리 뷰
[Keyword] : ML density estimation
DNN을 학습할 때 사용되는 Loss function은 다양한 Viewpoint 에서 해석할 수 있음
(CE Loss function VS MSE Loss function 무엇이 더 좋은가 ! Viewpoint 따라 다름)
[V1] Back-propagation 알고리즘이 더 잘 동작(gradient-vanishing 덜 발생)할 수 있는지에 대한 해석
→ CE가 더 좋음
[V2] Negative Maximum likelihood로 보고 특정 형태의 loss는 특정 형태의 확률분포를 가정한다는 해석
→ Output value가 Continuous : MSE & Discrete : CE 사용
→ 확률분포가 Gaussian distribution 따르면 MSE & Bernoulli distribution 따르면 CE 사용
∴ AutoEncoder DNN 학습하는 것 = ML density estimation 관점에서의 최적화 !
1. Machine Learning problem
1) Collect training data
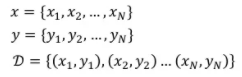
2) Define functions (Model / Loss)

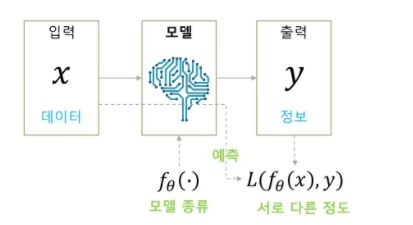
(1) Model (Output)
- 모델로 DNN 사용 + DNN 네트워크 구조 (CNN layer 몇개, RNN, ...) 정하고 들어감
- 모델의 파라미터는 Weight, Bias로 구성됨
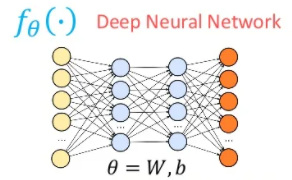
(2) Loss

- Loss : 모델의 output과 정답 라벨 y 값의 다른 정도
- DNN Loss function : MSE, CE
★ Backpropagation 통해 DNN 학습시킬 때 필요한 Loss function 조건(가정)
- Assumption 1 : Total loss of DNN over training samples = The Sum of loss for each training sample
- Assumption 2 : Loss for each training example is a function of Final Output of DNN
Loss function의 입력인자 = 정답라벨, 네트워크의 출력값
3) Learning (Training)
: Find the optimal parameter (training DB 전체에 대한 Loss를 minimize)
BY Gradient Descent

(1) Gradient Descent

GD = Iterative method
① How to update parameter θ : Loss 값이 줄어드는 방향으로 이동
② When stop : 더 이동해도 Loss 값이 변함 없을 때
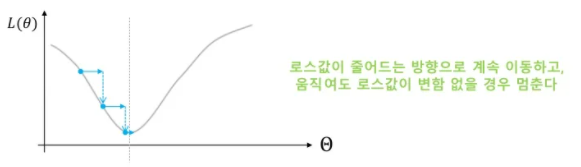
③ How to find △ θ (어떻게, 얼만큼씩 바꿔야 Loss가 줄어들까)
- Taylor Expansion & Approximation 이용
- 더 많은 차수를 사용할수록 더 넓은 지역까지 Approximation 오차가 작음
- 1차 미분만 쓴다는 것 = 그 근방에서만 맞는 Approximation 하겠다는 의미
△θ = - η▽L → △L < 0 (원하는 바)
η = 0.000001 (Sample point 근방에서만 Approximation 맞기에 lr을 굉장히 작게 설정함)

∴ 전체 SGD (parameter update) 과정


(2) Gradient Descent + Backpropagation
Backpropagation
맨 마지막 단인 output layer의 error signal 구함
→ 각 layers의 error signals 구함
→ 제일 앞단까지 error signals 구할 수 있음


4) Predicting (Testing)
Predicting (Testing) : Compute optimal function output
거의 대부분 :: 고정 입력 → 고정 출력

2. Loss function viewpoints 1 : Back-propagation
1) MSE / Quadratic Loss
Random Initialization 했을 때 두 그래프 차이가 많이 남 (왼쪽이 good, 오른쪽은 초기에 학습 X)
∵ Parameter 초기값이 달라서 차이가 생긴 것
Backprop 수식 자체에 Activation function 미분값이 포함되어 있기에
Activation function 미분값이 0에 가까울 경우, Gradient 값이 0이 되어 parameter update X (학습X)
Ex) Sigmoid의 gradient 최댓값은 1/4 → 한 layer 지날 때마다 Error signal이 1/4씩 떨어져서 0에 수렴
→ 앞단에서는 update 안되는 gradient vanishing problem 발생 → ReLU로 해결!


2) CE Loss
Backprop 초기값 (Error at output layer) 수식에 Activation function 미분값 포함 X
→ 초기값에 둔감(학습에 강인) → 같은 초기값에 대해 MSE 보다 CE Loss 썼을 때 학습이 더 잘 됨
MSE와 달리 처음에 1/4 줄지 않고 시작할 수 있음 !


3. Loss function viewpoints 2 : Maximum likelihood
1) 핵심
Network의 출력값 p( y | f(x) ) = 우리가 정해놓은 확률분포 모델의 Parameter (Likelihood 값이 X)
2) Define functions
Conditional probability 확률분포 모델을 추가로 정하고 시작 (Ex. Gaussian, Bernoulli)
모델의 Parameter를 추정하는 것 (Ex. Gaussian 모델이면 평균이랑 표준편차)
3) Learning (Training)
(1) Model Output
Network의 출력값(확률분포 모델의 평균값)이 Given 일 때,
원하는 정답 y가 나올 확률을 최대로 하고 싶음
= 확률분포에 대한 Maximum Likelihood (확률) 값 찾고 싶음
← When? 확률분포 모델의 평균값 = 정답 y값
(2) Loss : - log p
iid Condition 성립함
(3) 장점
확률분포 모델을 찾은 것이므로 Sampling 가능
고정 입력 → 고정 / 다른 출력





4. Maximum likelihood for AutoEncoders

DNN을 학습할 때 사용되는 Loss function은 다양한 Viewpoint 에서 해석할 수 있음
(CE Loss function VS MSE Loss function 무엇이 더 좋은가 ! Viewpoint 따라 다름)
[V1] Back-propagation 알고리즘이 더 잘 동작(gradient-vanishing 덜 발생)할 수 있는지에 대한 해석
→ CE가 더 좋음
[V2] Negative Maximum likelihood로 보고 특정 형태의 loss는 특정 형태의 확률분포를 가정한다는 해석
→ Output value가 Continuous : MSE & Discrete : CE 사용
→ 확률분포가 Gaussian distribution 따르면 MSE & Bernoulli distribution 따르면 CE 사용
∴ AutoEncoder DNN 학습하는 것 = ML density estimation 관점에서의 최적화 !
| AutoEncoder | Variational AE | |
| Probability distribution | p(x|x) | p(x) |
| Gaussian (Continuous) | MSE Loss | MSE Loss |
| Bernoulli (Categorical) | CE Loss | CE Loss |
'DL > AutoEncoder' 카테고리의 다른 글
| [Ch5] Applications (Retrieval, Generation, GAN+VAE) (0) | 2022.02.22 |
|---|---|
| [Ch4] Variational AutoEncoders (VAE, CVAE, AAE) (0) | 2022.01.31 |
| [Ch3] AutoEncoders (AE, DAE, CAE) (0) | 2022.01.30 |
| [Ch2] Manifold Learning (0) | 2022.01.30 |
| [Ch0] AutoEncoder (0) | 2022.01.30 |