
티스토리 뷰
1. Retrieval
Information Retrieval via AE
AE : Good at 'Data Dimension Reduction' (= Feature 잘 뽑음)


2. Generation
1) Gray Face / Handwritten Digits
(1) Gray Face Generation

VAE : Normal distribution (Prior) 공간 내에서 Sampling 하고 Generator에 입력하면 z값에 따라 다양한 이미지 생성 가능
z를 29 Dimension으로 압축했으며, 각 element 별로 주요한 feature들이 저절로 뽑히게 됨
(Vanilla VAE에서는 z의 각 element가 어떤 feature를 의미하는지 모름)
(2) Handwritten Digits Generation

Conditional VAE : 숫자 Lable 정보를 Condition으로 주는 VAE
z를 12 Dimension으로 압축했으며, 각 element 별로 Style 정보가 저절로 담김 (어떤 feature를 의미하는지 모름)
2) Deep Feature Consistent VAE
Reconstruction loss 구할 때..
(1) VAE vs GAN
- VAE : Pixel-wise로 구한 후 Sum 함으로써 mean loss 구해서 minimize → Blurry 하고 Train DB 평균적 이미지 생성
- GAN : Image-wise로 통째로 구해서 minimize → Sharp 하고 좀 더 그럴싸한 이미지 생성
(2) Vanilla VAE vs DFCVAE
- Vanilla VAE Loss = Pixel-wise Reconstruction Loss + KL Divergence Loss → Blurry
- Deep Feature Consistent VAE = CNN Feature level Reconstruction Loss + KL Divergence Loss → Sharp
(Image space에서 차이를 구하지 않고, Image를 CNN(VGGNet)에 태워서 CNN의 Feature level에서 차이를 구함)


3) Sketch RNN

3. GAN+VAE
Condition을 넣어주고 싶을 때 VAE로 학습된 Encoder로 압축해서 Generator에 넣어주는 경우가 많음
Reconstruction 했을 때 Generation 된 것이 실제랑 가까운지에 대해서는 GAN Loss 추가
1) Comparison bw VAE vs GAN
VAE : Encoder와 Decoder 모두 ELBO를 Maximize (=Loss를 Minimize) 하는 방향으로 협력 학습 (Easy)
GAN : Value function을 Discriminator는 Maximize, Generator는 Minimize 하도록 적대적 학습 (Hard)
+ GAN은 Mode collapsing, Unstable convergence 문제도 있어서 학습 더 Hard

2D에서의 검정 실선 (Mode) : 실제 이미지 공간의 samples (이미지 sample 하나가 점 하나)
검정 실선 3개를 다 익히는 것 = 완벽하게 확률분포 익히는 것
VAE : Explicit Density Estimation (확률분포 모델을 가정하고 시작)
→ 실선 3개를 잘 아우르면서 conditional Gaussian 분포를 따르는 모양으로 학습
→ 중간에서도 sampling 하다보니 Blurry하고 덜 진짜 같은 이미지들 생성됨
GAN : Implicit Density Estimation (G가 만든 Fake를 D가 Real로 구분하면 학습 끝남)
→ G가 하나의 실선만 완벽히 익히면, D는 그 실선에 대해서는 구분 불가하므로 학습 끝나게 됨 ; Mode collapse
→ 진짜 같은 Sharp한 이미지 생성되지만, Mode collapse 문제 있음(Mode 여러 개일때 하나만 학습됨)

2) Regularized AE : EBGAN, BEGAN
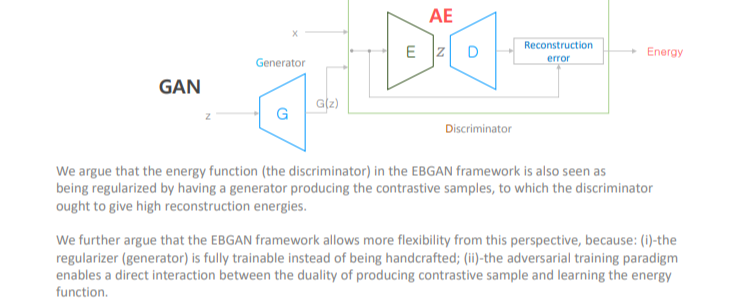
(1) EBGAN (Energy-Based GAN)
GAN의 Discriminator 대신 AE 두고,
Real sample이면 Reconstruction error ↓
Fake sample이면 Reconstruction error ↑
원래 GAN 보다 학습이 잘 됨!
(2) BEGAN (Boundary Equilibrium GAN)
GAN의 Discriminator 대신 AE 두는 EBGAN과 같은 구조인데,
Generator와 Discriminator의 balance를 맞추기 위한 Equilibrium factor를 추가해서 학습
3) Multimodel Feature Learner
(1) StackGAN
- StackGAN : Text로 Condition을 주고 이미지 생성해봐라
- VAE : GAN Generator에 Domain과 다른 정보를 Condition으로 넣어주기 위한 추상화된 Feature 잘 뽑아냄


Word2Vec으로 Input text data Vector 만들어서 Condition으로 그대로 Generator에 입력하는게 X
추상화된 feature를 잘 뽑기 위해서 VAE에 먼저 입력해서 Input text data Vector 대해 한번 학습 진행 후,
학습된 VAE의 Encoder 부분만 이용해서 text에 대한 추상적인 feature를 뽑아서 Condition으로 Generator에 입력
+ 똑같은 text 이지만, 다양한 style의 이미지 만들기 위해 random noise z 넣음 → Upsampling → 64x64 img 생성
압축한 문장을 한번 더 Generator에 Condition으로 입력해 똑같은 방식의 학습 진행 → Upsampling → 256x256 img 생성
(2) 3DGAN
- 3DGAN : 2D img를 Condition으로 입력하면 이에 맞는 3D model을 자동으로 생성
- VAE: GAN Generator의 Condition으로 넣어주기 위한 2D img에 대한 feature 뽑기 위해 사용

2D img에 대한 feature를 잘 뽑기 위해 VAE로 학습하고,
학습된 VAE의 Encoder 부분만 이용해서 data 압축하면 condition vector 생성됨
+ 다양한 3D model 생성하기 위해 random vector도 넣음
condition vector와 random vector를 GAN의 Generator에 입력해서 3D model 생성
Blurry 줄이기 위해, 생성된 3D model이 진짜 같은지 안같은지 별도로 둔 Discriminator가 구분하도록 학습
4) Denoising : SEGAN (Speech Enhancement GAN)

5) Age Progression/Regression by Conditional AAE
- 목적 : 이미지를 입력하고 나이를 Condition으로 줘서 그 나이에 해당되는 이미지 생성
- AAE : Prior distribution을 Uniform distribution으로 정함 (나이 드는 정도를 일정하게 하고자)
학습된 Manifold에서 나오는 sample이 Uniform distribution 따르도록 Discriminator 둠 (KL Term 사용 X)
- Decoding 해서 나온 결과 Output face가 Input face와 같도록 Reconstruction loss (L2 loss)
- Blurry 줄이기 위해, Generation 된 결과가 실제 Real과 비슷하게 되도록 별도의 Discriminator 둬서 학습시킴



6) PaletteNet : Image Recolorization with given color palette
- Palette 정보를 Condition으로 줌
- Color 만 바꾸기 위해 I_ab


7) Transformative Discriminative Autoencoders
[Hallucinating Very Low-Resolution Unaligned and Noisy Face Images by Transformative Discriminative AE]
: {Noise + Spatial Deformation} 시킨 16x16 을 128x128 로 복원할 때 VAE 사용


8) A Generative Model of People in Clothing
- Fashion Generating
- Human pose (part) 정보를 Condition으로 줌
- Segmentation을 실사 사진으로 바꾸는 건 pix2pix 구조 사용


GAN 안정적인 학습을 위한 모델 논문 모음
https://github.com/hwalsuklee/tensorflow-generative-model-collections
GAN 학습 노하우 모음
https://github.com/soumith/ganhacks
'DL > AutoEncoder' 카테고리의 다른 글
| [Ch4] Variational AutoEncoders (VAE, CVAE, AAE) (0) | 2022.01.31 |
|---|---|
| [Ch3] AutoEncoders (AE, DAE, CAE) (0) | 2022.01.30 |
| [Ch2] Manifold Learning (0) | 2022.01.30 |
| [Ch1] Revisit Deep Neural Networks (0) | 2022.01.30 |
| [Ch0] AutoEncoder (0) | 2022.01.30 |