
티스토리 뷰
6.1 RNN의 발달 과정
RNN : 순서가 있는 데이터에서 의미(패턴, 상관관계, 인과관계 등)를 찾아내기 위해 고안된 모델
시퀀스(sequence) 데이터 : 순서가 존재하는 데이터 (ex. 언어)
시계열(time series) 데이터 : 순서가 존재하며 시간에 따른 의미도 존재하는 데이터 (ex. 주가)
Application

6.2 RNN의 작동 원리
1) RNN 도식화



은닉층의 node들은 어떤 초기값을 가지고 계산이 시작되며,
t=0시점에서 입력값 + 각 node 초기값의 조합으로 t=0일 때 은닉층의 값들이 계산되어 결과값(출력값)이 도출됨
t=1시점에서 입력값 + t=0시점에서 계산된 은닉층 값들의 조합으로 t=1일 때 은닉층의 값과 결과값이 다시 계산됨
이러한 과정이 지정한 시간만큼 반복됨
2) 시간에 따른 역전파 Backpropagation through time (BPTT)
(1) RNN은 계산에 사용된 '시점의 수'에 영향을 받음
ex. t=0 ~ t=2 까지 계산에 사용됐다면 그 시간 전체에 대한 backprop 해야 함
(2) t=2시점의 loss를 backprop 하려면?
- loss를 입력과 은닉층들 사이의 가중치로 미분해 loss에 대한 각각의 비중을 구해 update
그 과정에서 은닉층의 이전 시점의 값들(=가중치 + 입력값 + 이전 시점의 값들)이 연산에 포함됨
- RNN은 각 위치별로 같은 가중치를 공유하므로 t=0시점의 node값들에도 영향을 줘야 함
시간을 역으로 거슬러 올라가는 방식으로 각 가중치를 update = BPTT




t=2시점에서 발생한 loss는 t=2, 1, 0시점에 전부 영향을 줌
t=1시점에서 발생한 loss는 t=1, 0 시점에 영향을 줌
t=0시점의 loss는 t=0의 가중치에 영향을 줌
실제 update할 때는 가중치에 대해 시점별 기울기를 다 더하여 한 번에 update 진행
6.3 모델 구현, 학습 및 결과 확인
1) Hyperparameter Setting 및 필요한 함수 구현
# Hyperparameter Setting
n_hidden = 35
lr = 0.01
epochs = 1000
string = "hello pytorch. how long can a rnn cell remember? show me your limit!"
chars = "abcdefghijklmnopqrstuvwxyz ?!.,:;01"
char_list = [i for i in chars]
n_letters = len(char_list)
# 문자열을 one-hot 벡터의 스택으로 만드는 함수
def string_to_onehot(string):
start = np.zeros(shape=n_letters ,dtype=int)
end = np.zeros(shape=n_letters ,dtype=int)
start[-2] = 1
end[-1] = 1
for i in string:
idx = char_list.index(i)
zero = np.zeros(shape=n_letters ,dtype=int)
zero[idx]=1
start = np.vstack([start,zero])
output = np.vstack([start,end])
return output
# One-hot 벡터를 문자로 바꿔주는 함수
def onehot_to_word(onehot_1):
onehot = torch.Tensor.numpy(onehot_1)
return char_list[onehot.argmax()]
2) RNN with 1 hidden layer
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.act_fn = nn.Tanh()
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1) # input과 hidden state를 cat
hidden = self.act_fn(self.i2h(combined)) # hidden state는 update
output = self.i2o(combined) # output은 계산
return output, hidden
def init_hidden(self): # 아직 입력이 없을 때(t=0)의 hidden state 초기화
return torch.zeros(1, self.hidden_size)
rnn = RNN(n_letters, n_hidden, n_letters)
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=lr)
3) Train
(1) one_hot : start_token + 문장 + end_token 으로 구성된 matrix 생성
(2) for i in range ~ : 문장 전체를 학습하는 과정은 epochs 만큼 반복하며 문장 전체에 대한 loss 계산 (매번 loss 초기화 진행)
(3) for j in range ~ : start_token이 들어오면 결과값으로 p가 나옴 → p가 들어오면 y가 나옴 → y가 들어오면 t가 나옴 → ....
j번째 인덱스에 해당하는 값이 input으로 들어오면 j+1번째 인덱스에 해당하는 값이 target이 됨
# Train
one_hot = torch.from_numpy(string_to_onehot(string)).type_as(torch.FloatTensor())
for i in range(epochs):
optimizer.zero_grad()
hidden = rnn.init_hidden()
total_loss = 0
for j in range(one_hot.size()[0]-1):
input_ = one_hot[j:j+1,:] # 입력값은 앞에 글자 (p y t o r c)
target = one_hot[j+1] # 목표값은 뒤에 글자 (y t o r c h)
output, hidden = rnn.forward(input_, hidden)
loss = loss_func(output.view(-1),target.view(-1))
total_loss += loss
total_loss.backward()
optimizer.step()
if i % 10 == 0:
print(total_loss)
4) Test
문장의 첫 글자만 입력으로 전달하고, 모델에서 나온 결과값이 새로운 입력으로 전달되는 방식으로 전체 문장 생성
# Test
start = torch.zeros(1,n_letters)
start[:,-2] = 1
with torch.no_grad():
hidden = rnn.init_hidden()
input_ = start
output_string = ""
for i in range(len(string)):
output, hidden = rnn.forward(input_, hidden)
output_string += onehot_to_word(output.data)
input_ = output
print(output_string)
6.4 RNN의 한계 및 개선 방안
1) 한계
: 타임 시퀀스가 늘어날수록 (긴 문장일수록) backprop 시 tanh의 미분값(0~1 사이의 값)이 여러 번 곱해지며
Vanishing Gradient 현상이 발생해 학습 제대로 되지 X

2) 개선 방안
(1) LSTM (Long Short-Term Memory)
: 기존의 RNN 모델에 장기기억을 담당하는 Cell State 부분을 추가한 모델
남길 건 남기고, 잊을 건 잊고, 새로 추가할 건 추가해서 Cell State에는 중요한 정보만 계속 흘러가도록! by using Gates
각 time step의 output이라고 할 수 있는 Hidden State는 Cell State를 적당히 가공해서 내보냄
Gate = g_t = sigmoid(W_g * V_input) : 0~1 사이 값을 갖는 elements로 구성된 vector
C_(t-1) * G : element-wise coefficient multiplication → 각 dimension의 정보를 pass할지 block할지 조절!




Cell State (셀 상태)
: 장기기억을 담당하는 부분
- 곱하기(X) 부분 : 기존 정보를 얼마나 남길 것인지에 따라 비중을 곱하는 부분
- 더하기(+) 부분 : 현재 들어온 데이터와 기존의 Hidden State를 통해 정보를 추가하는 부분

Forget Gate (망각 게이트)
: 기존의 정보들로 구성되어 있는 Cell State의 값을 얼마나 잊어버릴 것인지 비중을 정하는 부분
= 현재 시점에서의 입력값 x_t + 직전 시점의 Hidden State 값 h_(t-1)을 입력으로 받아서,
→ 각 입력에 가중치 w를 곱해주고 편차 b를 더한 값을 sigmoid 함수에 넣어 0~1 사이의 값을 출력
1️⃣ f_t 를 통해 C_(t-1)에서 불필요한 정보를 지움

Input Gate (입력 게이트)
: 어떤 정보를 얼만큼 Cell State에 새로 저장할 것인지 정하는 부분
새로운 입력값 x_t과 직전 시점의 Hidden State 값 h_(t-1)을 입력으로 받아서,
- sigmoid 함수 통과 : 0~1 사이의 값 출력 → 새롭게 추가할 정보를 얼만큼의 비중으로 Cell State에 더해줄지 정함
- tanh 통과 : -1~1 사이의 값 출력 → 새롭게 Cell State에 정보 추가 (임시 Cell State 값)
2️⃣ C_(t-1)에 새로운 입력값 x_t와 h_(t-1)을 보고 중요한 정보를 입력함 & 임시 ~C_t를 계산
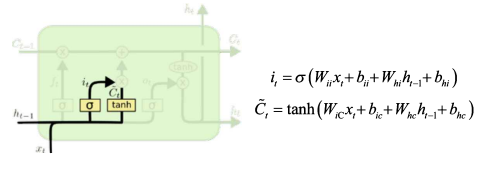
① Cell State UPDATE
현재 시점의 새로운 입력값 + 직전 시점의 Hidden State 값의 조합으로
기존 Cell State 정보 C_(t-1)를 얼만큼 forget하고 전달할지
& 어떤 정보 ~C_t를 얼만큼의 비중으로 더할지 정함
3️⃣ 위 두 과정을 통해 C_t 만듦 (update) : f_t로 C_(t-1)의 불필요한 정보를 날리고, 임시 C_t 정보를 추가

② Hidden State UPDATE
Sigmoid 비중을 정하는 부분은 앞단과 동일
새로운 Hidden State는 UPDATE된 Cell State 값을 tanh에 통과시킨 -1~1 사이의 비중을 곱한 값으로 생성됨
4️⃣ C_t를 적절히 가공해 해당 t에서의 h_t를 만듦 (update) : C_t를 가공할 output gate o_t로 h_t 계산

5️⃣ C_t와 h_t를 next step인 t+1로 전달
Q) LSTM은 어떻게 Vanishing Gradient 문제 해결 ?
: t시점에서 Cell State에 기록된 정보가 지워지지 않고 t+n에서 활용되었을 때,
중간에 Nonlinear act function 거치지 않고 흐른 것이기에 Vanishing Gradient 문제 일부 해소 가능!
(2) GRU (Gated Recurrent Unit)
- LSTM보다 간단한 구조이지만 성능 면에서 밀리지 않는 모델
- LSTM과 달리 Cell State와 Hidden State를 분리하지 않고, Hidden State 하나로 합침

① Update gate (z_t)
: 현 시점의 새 입력값 x_t와 직전 시점의 Hidden State 값 h_(t-1)에 가중치 곱하고 sigmoid 통과시켜 update 비중 정함
② Reset gate (r_t)
: Update gate와 동일한 입력, sigmoid 통과시켜 ~h_t 구할 때 기존 Hidden State를 얼만큼 반영할지에 대한 비중 정함
→ ~h_t : 기존 Hidden State h_(t-1)에 가중치가 곱해진 값 + 새로운 입력값 x_t에 가중치 곱한 값을 tanh 통과시켜 구함
③ 새로운 Hidden State (h_t)
: 앞서 구한 가중치로 기존 Hidden State h_(t-1)과 ~h_t의 가중 합을 곱해 새로운 Hidden State 값 h_t 구함

3) RNN Application - MNIST Classification (many to one)
(1) RNN
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
hidden_size = 128
num_classes = 10
num_epochs = 2
batch_size = 100
learning_rate = 0.001
input_size = 28
sequence_length = 28
num_layers = 2
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
examples = iter(test_loader)
example_data, example_targets = examples.next()
for i in range(6):
plt.subplot(2,3,i+1)
plt.imshow(example_data[i][0], cmap='gray')
plt.show()
# many to one RNN
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first = True)
# x -> (batch_size, seq, input_size)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.rnn(x, h0)
# out -> (batch_size, seq, hidden_size)
# out -> (N, 28, 128)
out = out[:, -1, :]
# out -> (N, 128)
out = self.fc(out)
return out
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Train the model
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# origin shape: [100, 1, 28, 28]
# resized: [100, 28, 28]
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}')
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
n_correct = 0
n_samples = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device)
labels = labels.to(device)
outputs = model(images)
# max returns (value ,index)
_, predicted = torch.max(outputs.data, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
acc = 100.0 * n_correct / n_samples
print(f'Accuracy of the network on the 10000 test images: {acc} %')
(2) GRU
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(GRU, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first = True)
# x -> (batch_size, seq, input_size)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.gru(x, h0)
# out -> (batch_size, seq, hidden_size)
# out -> (N, 28, 128)
out = out[:, -1, :]
# out -> (N, 128)
out = self.fc(out)
return out
model = GRU(input_size, hidden_size, num_layers, num_classes).to(device)
(3) LSTM
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(LSTM, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first = True)
# x -> (batch_size, seq, input_size)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.lstm(x, (h0,c0)) #Tuple 형태
# out -> (batch_size, seq, hidden_size)
# out -> (N, 28, 128)
out = out[:, -1, :]
# out -> (N, 128)
out = self.fc(out)
return out
model = LSTM(input_size, hidden_size, num_layers, num_classes).to(device)
4) Embedding layer
(1) 등장 배경
One-hot vector의 한계점 : ① 의미적 연산 + ② 확장성 측면에서 한계점을 가짐
① 내적 = 0 → 연산을 통해 두 알파벳 or 단어 or 문장 간의 의미적 차이나 유사도(ex. cosine similarity) 구하는 것 불가능
② 하나의 요소가 추가될 때마다 vector 길이가 늘어남 → 기존 모델이 무의미해짐
(2) Embedding
: 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자형태인 vector로 바꾼 결과 혹은 그 일련의 과정 전체
= 알파벳이나 단어 같은 기본 단위 요소들을 일정한 길이를 가지는 vector 공간에 투영하는 것
ex. Word Embedding : 일정한 크기의 vector에 단어들을 투영하는 방법 (의미적 공통점 가지는 단어끼리 유사한 값)

(3) 역할(기능)
- 단어/문장 간 관련도 계산(Word2Vex) : 단어를 전체 단어들 간의 관계에 맞춰 해당 단어의 특성을 갖는 vector로 변경
- 의미적/문법적 정보 함축 → 단어 vector 간 사칙 연산 가능
- 전이 학습(Transfer learning) : 모델의 성능과 수렴속도가 빠른 임베딩을 다른 딥러닝 모델의 입력값으로 사용 가능
- 특정 도메인에서 임베딩 해두면 비슷한 의미를 가지는 단어들끼리 가까운 곳에 위치하게 되므로 유사 단어 찾기 편리
(4) 대표적인 기법

① CBOW (Continuous Bag-Of-Words)
: '주변 단어들'로부터 '가운데 들어갈 단어 하나'가 나오도록 모델을 학습해 임베딩 벡터를 얻는 방식
- 문장 또는 문서의 모든 문장을 이 방식으로 학습하면 문서에서 사용된 단어들이 의미적(semantically)으로 임베딩됨
(ex. 'The quick brown dog jumps over the laxy fox' 에서 'dog'와 'fox'는 vector 공간상 가까운 위치에 임베딩됨)
② skip-gram
: '중심 단어'로부터 '주변 단어들'이 나오도록 모델을 학습해 임베딩 벡터를 얻는 방식
(ex. 'fox'가 들어오면 'quick', 'brown', 'jumps' 등의 단어들이 나오도록 학습됨)
- 학습 과정을 끝낸 후 가중치 행렬의 각 행을 단어 vector로 사용함
- CBOW로 만든 단어 vector 보다 단어 간의 유사도를 잘 측정하며 복잡한 특징도 잘 잡아냄 (일반적으로 성능 더 좋음)
(5) Embedding 함수를 이용한 LSTM, GRU 모델 구현
torch.nn.Embedding class 이용해서 Embedding instance 생성
→ 문자가 입력으로 들어오면 먼저 문자 사전(ASCII)에 의해 Index로 변환됨
→ 이 Index를 Embedding instance에 전달하면 vector가 결과로 나옴
→ 이 vector를 가지고 RNN, LSTM, GRU를 통해 모델을 학습시킴 !


◾ 공통 코드
◾ LSTM (Long Short-Term Memory)
◾ GRU (Gated Recurrent Unit)
'DL > Pytorch' 카테고리의 다른 글
| [Ch8] Neural Style Transfer (0) | 2022.01.24 |
|---|---|
| [Ch7] 학습 시 생길 수 있는 문제점 및 해결방안 (0) | 2022.01.22 |
| [Ch5] 합성곱 신경망(CNN) (0) | 2022.01.15 |
| [Ch4] 인공 신경망(ANN) (0) | 2022.01.15 |
| [Ch3] 선형회귀분석 (0) | 2022.01.15 |