
티스토리 뷰
7.1 Underfitting, Overfitting
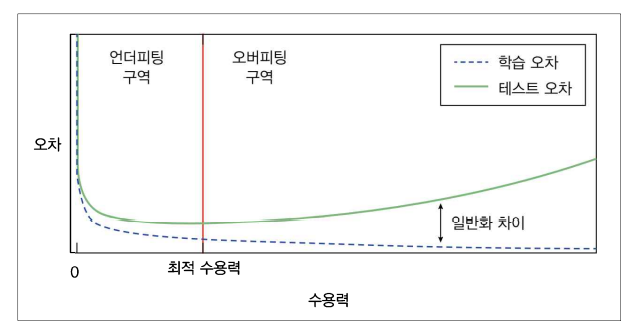
일반화 차이 = 테스트 오차 - 학습 오차
테스트 오차 = 학습오차 + 일반화 차이
평균제곱오차 = 편차의 제곱 + 분산 + 줄일 수 없는 오차 = Fixed
→ Bias와 Variance는 반비례 관계


| 학습 오차 ↑ | 학습 오차 ↓ | |
| 일반화 차이 ↑ | Underfitting | Overfitting |
| 일반화 차이 ↓ | Underfitting | Ideal state |
Underfitting : 학습 오차 ↑ = High Bias + Low Variance
Overfitting : 학습 오차는 ↓ but 테스트 오차 ↑ = High Variance + Low bias
7.2 Regularization
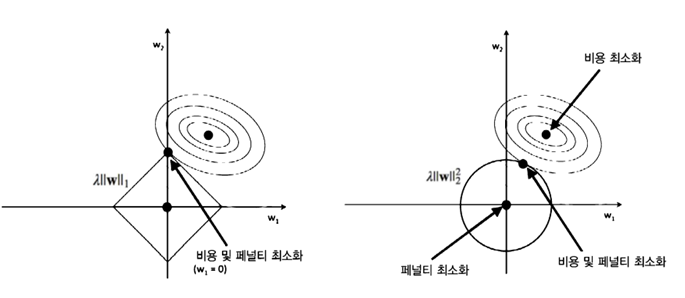
1) Regularization(정형화) : 어떤 제약조건을 (주로 손실 함수에) 추가로 걸어줌으로써 Overfitting을 해결하려는 기법
λ : Regularization의 정도 → lnλ 가 커질수록 가중치 계수(w)들이 작아짐 = Overfitting 구간 벗어날 수 있음
ex) L1 Regularization , L2 Regularization

https://jeonggg119.tistory.com/18#:~:text=6.%20Regularization%20Shrinkage%20Method
[DS] 통계기초/회귀분석
1. 통계기초 1) ML : 지도학습(회귀, 분류) + 비지도학습(군집화, 변화, 연관) + 강화학습 독립변수, 종속변수가 존재할 때 - 회귀(Regression) : 예측하고 싶은 종속변수가 숫자(수치형 데이터)일 때 사
jeonggg119.tistory.com
w* = 평균제곱오차 + Penalty항
전체 식을 minimize 하려면 w가 작아져야 함
→ 목표 : 실제 데이터와 예측값의 오차를 줄이되 작은 w값으로 이를 달성
2) Pytorch Regularization
(1) 기존 Loss function에 Regularization 식을 명시적으로 추가
: 가중치 값에 접근해서 절댓값의 합을 구하거나 제곱의 합을 구해 기존의 평균제곱오차에 직접 더해 이를 최적화
# nn.MSELoss()
for m in self.modules():
m.weight.data
(2) 최적화 함수에 weight_decay 인수 추가
weight_decay = λ : Hyperparameter (실험적으로 적절한 값 Tuning)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5) # L2
7.3 Dropout

1) Dropout (드롭아웃) : 특정 뉴런의 확률 p를 0으로 바꾸는 것
= p만큼 각 층의 수용력을 줄여 전체 모델의 수용력을 줄이는 것 (Overfitting 해결)
= 수용력이 낮은 모델들의 앙상블 효과 (테스트할 때는 Drop 하지 않고 합쳐짐)
테스트할 때는 모든 node의 값이 전부 전달되므로 문제가 생길 수 있기에, 학습 시의 상황과 맞춰주고자 Drop 확률을 곱해서 전달
ex) p=0.2였다면 학습 시에는 전체의 0.8이 전달된 것이므로, 테스트 시에는 전달된 값에 0.8을 곱해서 전달
2) Pytorch Dropout
1~3차원 데이터를 입력으로 받는 Dropout을 하나의 층처럼 사용할 수 있음
torch.nn.Dropout(p=0.5, inplace=False)p : 0이 될 확률
inplace=False : (default) 반환된 값을 다른 변수에 저장해야 함
inplace=True : 작업이 자체적으로 저장됨
model.train() 에서는 dropout = True & model.eval() 에서는 dropout = False
※ train()과 eval()에서 Dropout이 다르게 동작하므로 test 시에는 반드시 model.eval() 해줘야 함
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1,16,3,padding=1), # 28
nn.ReLU(),
nn.Dropout2d(0.2),
nn.Conv2d(16,32,3,padding=1), # 28
nn.ReLU(),
nn.Dropout2d(0.2),
nn.MaxPool2d(2,2), # 14
nn.Conv2d(32,64,3,padding=1), # 14
nn.ReLU(),
nn.Dropout2d(0.2),
nn.MaxPool2d(2,2) # 7
)
self.fc_layer = nn.Sequential(
nn.Linear(64*7*7,100),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(100,10)
)
def forward(self,x):
out = self.layer(x)
out = out.view(batch_size,-1)
out = self.fc_layer(out)
return out
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# set the model to train mode (dropout=True)
for i in range(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = image.to(device)
y_= label.to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
if i % 10 == 0:
print(loss)
# set the model to evaluation mode (dropout=False)
correct = 0
total = 0
model.eval()
with torch.no_grad():
for image,label in test_loader:
x = image.to(device)
y_= label.to(device)
output = model.forward(x)
_,output_index = torch.max(output,1)
total += label.size(0)
correct += (output_index == y_).sum().float()
print("Accuracy of Test Data: {}".format(100*correct/total))
7.4 Data Augmentation
1) torchvision.transforms 이용
mnist_train = dset.MNIST("./", train=True,
transform = transforms.Compose([
transforms.Resize(34), # 28x28 -> 34x34
transforms.CenterCrop(28), # 중앙 28x28 crop
transforms.RandomHorizontalFlip(), # 랜덤 좌우반전
transforms.Lambda(lambda x: x.rotate(90)), # 90도 회전 by 람다함수
transforms.ToTensor(), # 이미지를 텐서로 변형
]),
target_transform=None,
download=True)
mnist_test = dset.MNIST("./", train=False,
transform=transforms.ToTensor(),
target_transform=None,
download=True)2) Gaussian Noise 추가
3) Elastic deformation 등을 통해 이미지 변형
7.5 Initialization
1) Weight Initialization (가중치 초기화)
- 최적의 가중치의 값과 가까운 지점에서 학습을 시작할수록 빠르게 수렴할 수 있지만, 그 지점 자체는 모르는 값이므로 근처 시작 불가
- 대신, 학습 도중 기울기 소실 및 과다 현상을 방지하거나 Loss function 공간을 최적화에 쉬운 형태로 바꿈 = Weight Initialization
ex) Xavier Initialization, He Initialization
(1) Xavier Glorot Initialization
- 가중치의 초깃값을 N(0, var=2/(n_in + n_out)) 에서 뽑는 초기화 방법
n_in [n_out] : 해당 레이어에 들어오는 [나가는] 특성의 수
- 데이터가 몇 개의 레이어를 통과하더라고 활성화 값이 너무 커지거나 작아지지 않고 일정한 범위 안에 있도록 잡아줌
- 주로 sigmoid, tanh Activation function 사용할 때 사용
(2) Kaiming He Initialization
- 가중치의 초깃값을 N(0, var=2/( (1+a^2)*n_in )) 에서 뽑는 초기화 방법
n_in : 해당 레이어에 들어오는 특성의 수
a : ReLU or Leaky ReLU의 음수부분 기울기 (ReLU 사용 가정 하에 default=0)
- 주로 ReLU 계열 Activation function 사용할 때 사용
2) Pytorch Initialization
: 사용한 Activation function에 따라 (1), (2), (3) 방법 중 하나만 선택해서 모듈마다 적용
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
...........
# 모델의 모듈을 차례대로 불러오기
for m in self.modules():
# 모듈이 nn.Conv2d인 경우
if isinstance(m, nn.Conv2d):
# (1) 작은 숫자로 초기화하는 방법
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
# (2) Xavier Initialization
init.xavier_normal(m.weight.data)
m.bias.data.fill_(0)
# (3) Kaming He Initialization
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
# 모듈이 nn.Linear인 경우
elif isinstance(m, nn.Linear):
# (1) 작은 숫자로 초기화하는 방법
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
# (2) Xavier Initialization
init.xavier_normal(m.weight.data)
m.bias.data.fill_(0)
# (3) Kaming He Initialization
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
7.6 Learning rate
1) Learning rate (학습률) : 손실에 대한 가중치를 구하고 그 값과 학습률을 곱해 변수들을 업데이트
- Learning rate Decay : 초기에 비교적 높은 학습률로 시작해 점차 낮추는 전략
cf) batch size를 늘리는 게 더 좋다는 연구도 있음
- scheduler를 통해 매 epoch 마다 한 번씩 step을 호출
- optimizer를 인수로 받는 다양한 학습률 감소 함수 사용 가능 + 직접 정의도 가능
# (1) 지정한 스텝(epoch) 수 단위로 학습률에 감마를 곱해 학습률 감소
scheduler = lr_scheduler.StepLR(optimizer, step_size=1, gamma= 0.99)
# (2) 지정한 스텝 지점마다 학습률에 감마를 곱해 학습률 감소 (유연)
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[10,30,80], gamma= 0.1)
# (3) 매 epoch마다 학습률에 감마를 곱해 학습률 감소
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma= 0.99)loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = lr_scheduler.StepLR(optimizer, step_size=1, gamma= 0.99)
for i in range(num_epoch):
scheduler.step()
for j,[image,label] in enumerate(train_loader):
x = image.to(device)
y_= label.to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
7.7 Normalization
1) Normalization (정규화)
(1) 등장 배경 : 데이터 간의 분포가 다르다면 각 분포에 맞춰 변수가 업데이트 되므로 train, test 잘 안됨

(2) Standardization (표준화) : 데이터에서 평균을 빼고 표준편차로 나눠 표준정규분포화하는 정규화 방법
(x-mean)/std = x' ~ N(0,1)

(3) MinMax (최소극대화) : 데이터를 0 ~ 1 사이로 압축하거나 늘리는 정규화 방법
x = ( x - x.min ) / ( x.max - x.min ) : 0~1
- 일정 범위 내로 데이터 값들을 이동 시키긴 하지만, 너무 작거나 큰 이상치가 있는 경우엔 오히려 학습에 방해될 수 O
2) Pytorch Normalization (Standardization)
transforms.Normalize의 인수인 mean, std는 미리 계산된 값
- Mnist data : 1채널이므로 각각 1개씩 입력
- Imagenet data : 3채널이므로 각각 3개씩 입력
mnist_train = dset.MNIST("./", train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))
]),
target_transform=None,
download=True)
mnist_test = dset.MNIST("./", train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))
]),
target_transform=None,
download=True)
3) Normalization 중요성
- Normalization 안하면 ?
데이터의 각 요소별로 범위가 다르므로
어떤 변수 기준으로 학습률 정하는지에 따라 지그재그 모양으로 불필요한 update 많이 진행됨
- Normalization 하면 ?
정규화된 데이터는 변수들의 범위가 일정하므로
불필요한 update가 적으며 더 큰 학습률 적용 가능해서 일반적으로 학습이 더 잘 됨

7.8 Batch Normalization
1) Batch Normalization (배치 정규화)
(1) 등장 배경 : Internal Convariate Shift (내부 공변량 변화) = DL model 하나의 은닉층에 여러 범위의 입력이 들어옴
* Covariate Shift (공변량 변화) : 하나의 신경망에 대해 입력의 범위가 바뀌는 것

(2) Batch Normalization : 한 번에 입력으로 들어오는 batch 단위로 정규화하는 것
입력(mini-batch) B = {X_1,...,m} 에 대해 mean과 variance를 구하고 정규화 진행
→ 정규화된 데이터 x_i^을 scale & shift (학습되는 변수 : γ for scaling , β for shifting)
→ 다음 layer에 일정한 범위의 값들만 전달 (출력 : y_i = BN(x_i))
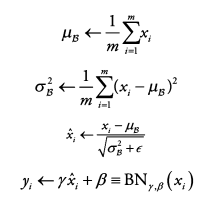
(3) BN 위치 : 합성곱 연산이나 선형변환 연산 사이 .. ex) DenseNet : BN - Act - Conv
(4) BN 장점 : 은닉층 단위마다 BN 넣어주면 내부 공변량 방지 + 더 큰 학습률 사용 가능
(5) 모드 2가지
- train() : train 시 batch 단위의 mean, variance를 차례대로 받아 이동평균, 이동분산을 구하여 저장
- eval() : test 시 해당 batch의 mean, variance를 구하지 않고, 구해놨던 값으로 정규화 진행
2) Pytorch Batch Normalization
torch.nn.BatchNorm2d(num_features)num_features : C from an expected input of size (N,C,H,W) = 입력 채널
model.train() 에서는 mean, variance 구함 & model.eval() 에서는 mean, variance 구하지 X
※ train()과 eval()에서 Batch Normalization 이 다르게 동작하므로 test 시에는 반드시 model.eval() 해줘야 함
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1,16,3,padding=1), # 28 x 28
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16,32,3,padding=1), # 28 x 28
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2,2), # 14 x 14
nn.Conv2d(32,64,3,padding=1), # 14 x 14
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2,2) # 7 x 7
)
self.fc_layer = nn.Sequential(
nn.Linear(64*7*7,100),
nn.BatchNorm1d(100),
nn.ReLU(),
nn.Linear(100,10)
)
def forward(self,x):
out = self.layer(x)
out = out.view(batch_size,-1)
out = self.fc_layer(out)
return out
3) Other Normalization method
(1) Instance Normalization (인스턴스 정규화) : batch 대신 data 하나당 정규화 진행
torch.nn.InstanceNorm2d(num_features)(2) Weight Normalization (은닉층 가중치 정규화) : large batch size일 때 BN보다 좋은 성능
7.9 Gradient Descent 변형
(1) 등장 배경
- Gradient Descent (GD) : 모든 데이터셋을 입력하기에 최적값 찾기 위한 학습 시간 오래 걸림
한번에 모든 데이터를 계산 (느림) / 최적의 한스텝을 나아감 / 확실하지만 너무 느림
- Stochastic Gradient Descent (SGD) : mini-batch size 만큼씩 데이터를 가져와 여러 번에 나눠 훈련 진행 - 성능 낮음
한번에 일부 데이터만 계산 (빠름) / 빠르게 전진 / 방향이 뒤죽박죽이라 성능이 낮음


optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
(2) 발전된 SGD
① Momentum
: 같은 방향으로 update가 여러 번 일어나게 되면 그 방향으로 점점 가속도가 붙어 더 많이 update 되도록 함으로써 빠르게 최소 지점에 가까워지도록 하는 방법
v : 속도, γ : 가속도

② NAG (Nesterov Accelerated Momentum)
가속도 자체는 과거의 값들로 구해진 값이므로 현재 시점의 기울기와 무관하게 update될 값임
→ NAG : 가속도에 대한 변수 update는 진행하고, 그 이후에 각 변수들의 gradient를 다시 구해서 한번 더 update하는 방법
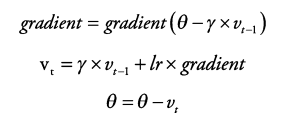

③ AdaGrad
: 기울기 누적 변수를 도입해 기울기가 적게 변한 변수는 한번에 크게 update (lr↑), 많이 변한 변수는 적게 update(lr↓)하는 방식 = 각각의 학습 파라미터의 update 횟수에 따라 '맞춤형'으로 lr 조정하는 옵션 추가
같은 입력 데이터가 여러 번 학습되는 모델에 유용 (ex. word2vec, GloVe)
update가 많이 필요한 변수에 대해서는 학습이 충분이 안 될 가능성도 O
optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)
④ RMSprop
Exponential Moving Average를 통해 lr을 조정하여 과거의 기울기는 점점 잊고 새로운 정보를 크게 반영
(AdaGrad로 학습을 계속 진행할수록 lr이 계속 작아져 0에 가까워져 학습이 불가능해질 수 있는 점을 해결)
⑤ AdaDelta
: decay rate 변수를 도입해 지정한 비율로 저장된 gradient를 decay 시키는 방식
optimizer = torch.optim.Adadelta(model.parameters(), lr=learning_rate)
⑥ Adam (RMSprop + Momentum)
: gradient의 1차 모멘트(mean), 2차 모멘트(variance)를 계산해 변수를 update하는 방식
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)

'DL > Pytorch' 카테고리의 다른 글
| [Ch9] 오토인코더(AE) (0) | 2022.01.31 |
|---|---|
| [Ch8] Neural Style Transfer (0) | 2022.01.24 |
| [Ch6] 순환신경망(RNN) (0) | 2022.01.20 |
| [Ch5] 합성곱 신경망(CNN) (0) | 2022.01.15 |
| [Ch4] 인공 신경망(ANN) (0) | 2022.01.15 |