
티스토리 뷰
8.1 Transfer learning
1) 전이학습 : 특정 조건에서 얻어진 어떤 지식을 다른 상황에 맞게 전이해서 활용하는 학습 방법
2) 전이되는 대상 : 학습한 필터
(ex. 이미지넷 데이터로 학습된 모델로 전이 학습 시, 범용적 형태를 구분할 수 있는 지식 전이)
3) 전이학습의 장점
(1) 데이터 부족 문제 해결
데이터가 적을 때 모델의 변수를 처음부터 학습하려고 하면 성능이 잘 나오지 X
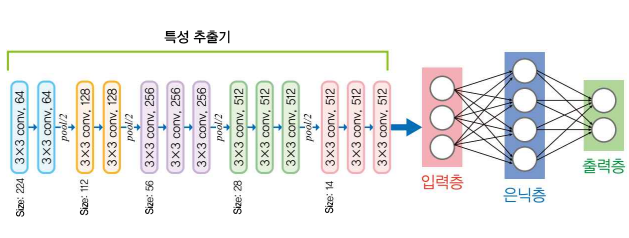
① 왼쪽 합성곱 연산 부분 : 이미지넷 같은 작업으로 미리 학습된 모델에서 last FC 떼어낸 것
= 특성 추출기(Feature Extractor) : 미리 학습된 부분(변수 고정). 이미지 입력받아 미리 학습된 필터들로 특성 추출
② 오른쪽 네트워크(입력층-은닉층-출력층) : 아직 학습 안 된 변수들로 이루어진 신경망. 이 변수들에 대해서만 학습
(2) 학습 시간 감소
현재 작업에 필요한 필터 조합만 추가적으로 학습하기에 학습 시간 적게 걸림
(3) 시뮬레이션에서 학습된 모델을 현실에 적용할 수 있게 해줌
ex. 자율주행차용 시뮬레이션 환경을 만들고, 거기서 학습된 변수들로 전이학습을 현실에서 진행
(4) Domain Adaptation 등 다양한 분야에서 활용
4) Transfer Learning Example Code : Pretrained ResNet-50
이미지넷으로 학습된 Pretrained ResNet-50의 앞단 + 다른 데이터셋에 적용하기 위해 뒷단 fc layer 추가
import torch
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# Hyperparameters
batch_size = 2
learning_rate = 0.001
num_epoch = 10
num_category = 2
# Data
img_dir = "./images"
img_data = dset.ImageFolder(img_dir, transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]))
train_loader = DataLoader(img_data, batch_size=batch_size,
shuffle=True, num_workers=2,drop_last=True)import torchvision.models as models
# 1) Pretrained Resnet
resnet = models.resnet50(pretrained=True)
for name, module in resnet.named_children():
print(name)
(1) Custom Resnet 모델 구조 정의
import torch.nn as nn
# 2) Fully Connected Model
# layer 0 : pretrained model의 parameters 가져옴
# layer 1 : 새로 만들어 이 부분에 대해 학습 진행
class Resnet(nn.Module):
def __init__(self):
super(Resnet,self).__init__()
self.layer0 = nn.Sequential(*list(resnet.children())[0:-1])
self.layer1 = nn.Sequential(
nn.Linear(2048,500),
nn.BatchNorm1d(500),
nn.ReLU(),
nn.Linear(500,num_category),
nn.ReLU()
)
def forward(self,x):
out = self.layer0(x)
out = out.view(batch_size,-1)
out= self.layer1(out)
return outdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Resnet().to(device)
# layer0의 파라미터들은 학습이 되지 않도록 기울기 계산 off
for params in model.layer0.parameters():
params.require_grad = False
# layer1의 파라미터들은 학습되도록 기울기 계산 ON
for params in model.layer1.parameters():
params.requires_grad = True8.2 Style Transfer
이미지넷 pretrained model은 이미지에서 특정한 형태를 구분할 수 있는 범용적인 필터들을 가짐
ex) 입력단에 가까운 layer에는 가로 선, 세로 선, 대각선, 색에 대해 반응하는 필터들이 학습됨
+ layer 깊어질수록 간단한 필터들의 조합으로 복잡한 형태를 구분할 수 있게 됨
8.3 Style and Content
1) Style : Correlations between different filter responses (다른 필터 응답들 간의 연관성)
필터 응답 : 활성화된 텐서
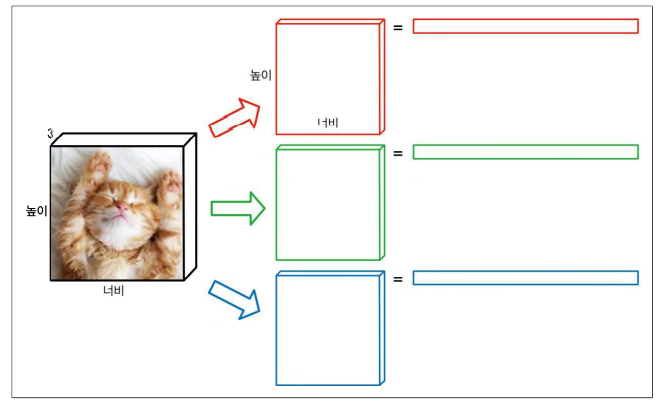
필터 응답, 활성화지도를 이용해 그람 행렬 만들고자 먼저 벡터화 진행 (일렬로 쭉펴기)
벡터화한 필터에 대한 활성화 값들ㄴ을 붙여 행렬화
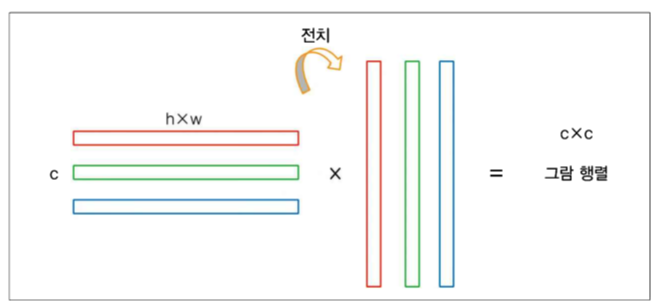
행은 필터의 개수 C, 열은 기존 이미지의 HxW 인 행렬 생성
이 행렬을 전치한 행렬과 곱해 그람 행렬 CxC 생성
그람 행렬 : 내적이 정의된 공간에서 벡터 v1, v2, ..., vn이 있을 때 가능한 모든 경우의 내적을 행렬로 표현한 것
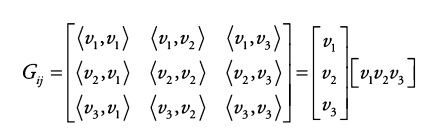
2) Content : Style과 대비되는 형태
Content representation : Feature response in higher layers of the network (더 높은 layer 내의 특성 응답)
특성 응답 = 활성화 지도
8.4 학습 알고리즘
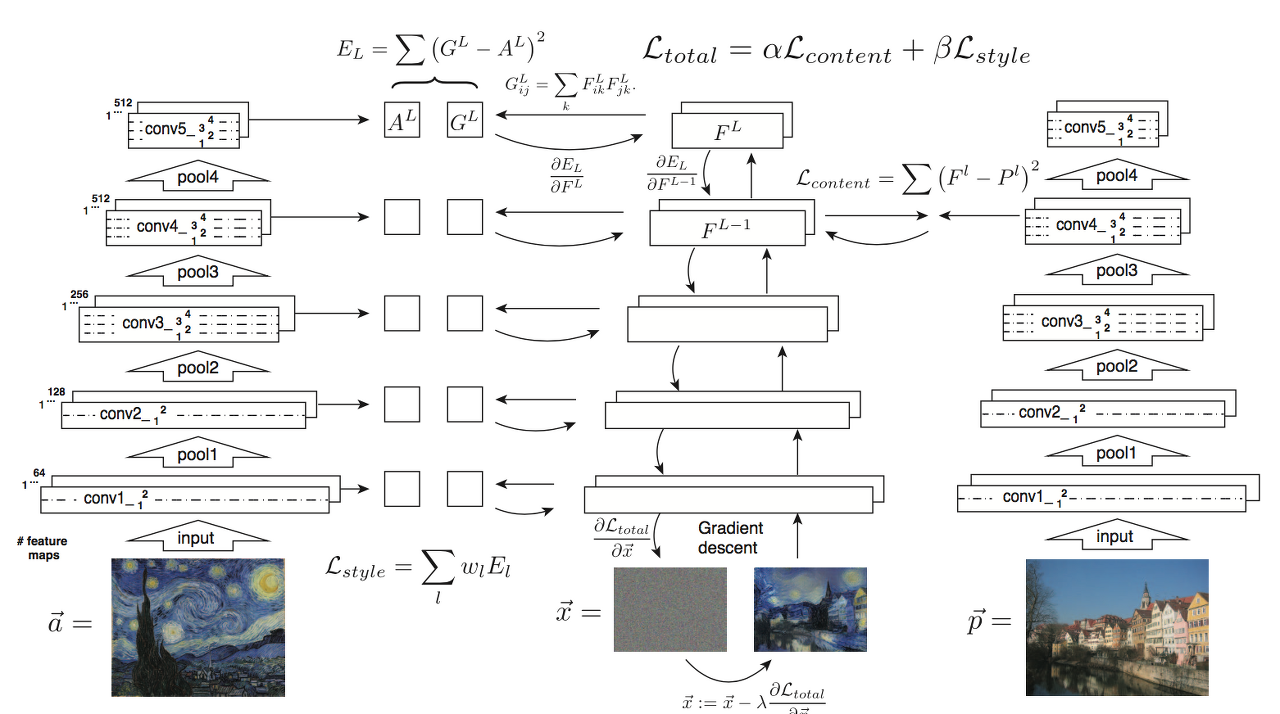
왼쪽 = Style 이미지, 가운데 = 학습의 대상 (결과 이미지), 오른쪽 = Content 이미지
1) 학습의 대상 : 결과 이미지 (모델의 변수가 X)
2) 최종 결과물 : Styler과 Content가 적절히 섞인 이미지
3) Pretrained model : Style과 Content를 뽑아내는 모델, 가운데 목표 이미지에서 Style과 Content를 뽑아내는 모델은 모두 이미지넷으로 pretrained 된 하나의 공통 모델
4) Total Loss = α * Content Loss + β * Style Loss .. 평균제곱오차 이용
왼쪽과 가운데를 비교해 Style Loss를 계산 & 가운데와 오른쪽을 비교해 Content Loss 계산
(1) Style Loss : 모든 위치에서 계산
: 모델의 위치에 따라 Receptive field가 달라지므로, Style을 서로 다른 Receptive field에서 뽑아냄으로써 좁은 영역의 세밀한 Style부터 넓은 영역의 전체적인 Style까지 다양하게 볼 수 있음
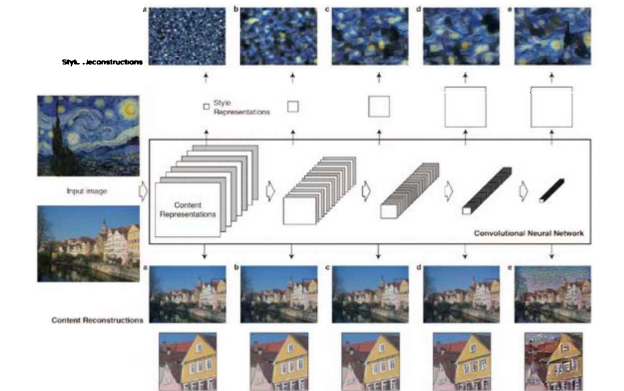
(2) Content Loss : conv_4에서만 계산

위 그림에서 가로축 = α / β 비율, 세로축 = 모델에서 Content Loss를 계산한 위치
- Style Loss의 가중치 β가 커질수록(왼쪽) 원래 그림의 형태가 사라지며,
- Content Loss를 계산한 위치가 입력 이미지에 가까워질수록(위쪽) 원본 이미지의 위치정보가 잘 유지됨
∴ conv_4 = 형태를 보존하면서도 스타일을 잘 입힐 수 있는 실험적 적절한 위치
8.5 최적화 알고리즘
(1) Newton's method

(1-1) Newton's method 변형
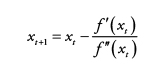
f(x)에 대해서 1차, 2차 미분 값이라는 더 많은 정보를 가지므로 1차 미분만 있는 것보다 근사 better 가능성
but 연산 속도 면에서는 1차 미분보다 느림 ~O(n^3)
(2) BFGS (Broyden-Fletcher-Goldfarb-Shanno)
: L-BFGS 값을 엄밀하게 계산하는 대신 근사하는 방식으로 바꿔 연산 속도를 높인 방식 ~O(n^2)
(3) L-BFGS (Limited-memory BFGS) : 2차 미분 값까지 이용
m개의 1차 미분 값만을 사용해 더 적은 메모리를 사용하도록 변형한 방식 ~O(mn)
8.6 코드 구현
# Hyperparameter
content_layer_num = 1 # Content Loss
image_size = 512
epoch = 5000
# Preprocessing Function
# Pretrained Resnet이 이미지넷으로 학습된 모델이기에 정규화 진행
def image_preprocess(img_dir):
img = Image.open(img_dir)
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.40760392, 0.45795686, 0.48501961],
std=[1,1,1]),
])
img = transform(img).view((-1,3,image_size,image_size))
return img
# Postprocessing Function
# 정규화된 상태로 연산하고 다시 이미지화해서 보기위해 뺐던 값들을 다시 더해줌
# 이미지가 0~1 사이의 값 갖도록 함
def image_postprocess(tensor):
transform = transforms.Normalize(mean=[-0.40760392, -0.45795686, -0.48501961],
std=[1,1,1])
img = transform(tensor.clone())
img = img.clamp(0,1)
img = torch.transpose(img,0,1)
img = torch.transpose(img,1,2)
return img# Pretrained Resnet
resnet = models.resnet50(pretrained=True)
# Custome Restnet deleted fc layer (layer별 접근 가능하도록 정의)
class Resnet(nn.Module):
def __init__(self):
super(Resnet,self).__init__()
self.layer0 = nn.Sequential(*list(resnet.children())[0:1])
self.layer1 = nn.Sequential(*list(resnet.children())[1:4])
self.layer2 = nn.Sequential(*list(resnet.children())[4:5])
self.layer3 = nn.Sequential(*list(resnet.children())[5:6])
self.layer4 = nn.Sequential(*list(resnet.children())[6:7])
self.layer5 = nn.Sequential(*list(resnet.children())[7:8])
def forward(self,x):
out_0 = self.layer0(x)
out_1 = self.layer1(out_0)
out_2 = self.layer2(out_1)
out_3 = self.layer3(out_2)
out_4 = self.layer4(out_3)
out_5 = self.layer5(out_4)
return out_0, out_1, out_2, out_3, out_4, out_5
# Gram Matrix function
# [batch,channel,height,width] -> [b,c,h*w]
# [b,c,h*w] x [b,h*w,c] = [b,c,c]
class GramMatrix(nn.Module):
def forward(self, input):
b,c,h,w = input.size()
F = input.view(b, c, h*w)
G = torch.bmm(F, F.transpose(1,2))
return G
# Model on GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
resnet = Resnet().to(device)
# 모델의 parameters는 학습대상이 아니므로 기울기 계산 off
for param in resnet.parameters():
param.requires_grad = False
# Gram Matrix Loss
class GramMSELoss(nn.Module):
def forward(self, input, target):
out = nn.MSELoss()(GramMatrix()(input), target)
return out# Prepare images & 시각화
content = image_preprocess(content_dir).to(device)
style = image_preprocess(style_dir).to(device)
generated = content.clone().requires_grad_().to(device)
print(content.requires_grad,style.requires_grad,generated.requires_grad)
plt.imshow(image_postprocess(content[0].cpu()))
plt.show()
plt.imshow(image_postprocess(style[0].cpu()))
plt.show()
gen_img = image_postprocess(generated[0].cpu()).data.numpy()
plt.imshow(gen_img)
plt.show()
# Set Targets(목표값) & Set Style Weights(행렬크기에 따른 가중치)
style_target = list(GramMatrix().to(device)(i) for i in resnet(style))
content_target = resnet(content)[content_layer_num]
style_weight = [1/n**2 for n in [64,64,256,512,1024,2048]]
# Train
# 학습대상은 모델 가중치가 아닌 이미지 자체
optimizer = optim.LBFGS([generated])
iteration = [0]
while iteration[0] < epoch:
def closure():
optimizer.zero_grad()
out = resnet(generated)
# 스타일 손실 = 각각의 목표값에 따라 계산하고 이를 리스트로 저장
style_loss = [GramMSELoss().to(device)(out[i],style_target[i])*style_weight[i] for i in range(len(style_target))]
# 컨텐츠 손실 = 지정한 위치에서만 계산되므로 하나의 수치로 저장됨
content_loss = nn.MSELoss().to(device)(out[content_layer_num],content_target)
# 스타일:컨텐츠 = 1000:1의 비중으로 총 손실 계산
total_loss = 1000 * sum(style_loss) + torch.sum(content_loss)
total_loss.backward()
if iteration[0] % 100 == 0:
print(total_loss)
iteration[0] += 1
return total_loss
optimizer.step(closure)
# Check Results
gen_img = image_postprocess(generated[0].cpu()).data.numpy()
plt.figure(figsize=(10,10))
plt.imshow(gen_img)
plt.show()
'DL > Pytorch' 카테고리의 다른 글
| [Ch10] 생성적 적대 신경망(GAN) (0) | 2022.02.02 |
|---|---|
| [Ch9] 오토인코더(AE) (0) | 2022.01.31 |
| [Ch7] 학습 시 생길 수 있는 문제점 및 해결방안 (0) | 2022.01.22 |
| [Ch6] 순환신경망(RNN) (0) | 2022.01.20 |
| [Ch5] 합성곱 신경망(CNN) (0) | 2022.01.15 |