
 [DA] WordCloud
[DA] WordCloud
1. WordCloud : 텍스트 데이터에서 단어들의 빈도수를 나타내는 그림 텍스트에서 빈도수가 높거나 중요한 단어 직관적 파악 가능 - 빈도수가 높은 단어일수록 더 크고 두껍게 나타남 - 텍스트 데이터의 주제를 파악하는 데 도움 2. 모듈 다운로드 및 설치 1) cmd conda install -c conda-forge wordcloud=1.5 # 설치 실패하거나 DLL load failed 에러 뜰 경우 conda remove pillow conda install -c conda-forge wordcloud=1.5 2) python shell from wordcloud import WordCloud, STOPWORDS as stopwords 3. WordCloud 만들기 1) text load 및 W..
 [DA] NLP Pipeline - NLTK & KoNLPy
[DA] NLP Pipeline - NLTK & KoNLPy
1. Introdunction to NLP 1) NLP (Natural Language Processing) : 자연어처리, 즉 우리가 일상생활에서 사용하는 언어의 의미를 분석해 컴퓨터가 처리할 수 있도록 하는 일 Ex. Sentiment Classification, Machine Translation 2) NLP Pipeline (1) Text Data (Corpus, 말뭉치, 코퍼스) (2) Data Preprocessing (데이터 전처리) + FE - Tokenization - Stemming or Lemmatization - Stopwords removal - Text Representation (3) Modeling (모델링) Train - Test - Evaluate Model 3) 관련 패..
 [Ch6] Spatial Filtering
[Ch6] Spatial Filtering
6.1 Introduction 1) Spatial Filtering Spatial Filtering : applying a function to a neighborhood of each pixel ① Move a 'mask' : a rectangle (usually with sides of odd length) or other shape over given img ② Create a new img whose pixels have grey values calculated from grey values under the mask 2) Linear Filter Filter : Combination of Mask and Function Linear Filter : Combination of Mask and Li..
 [Ch5] Pointing Processing
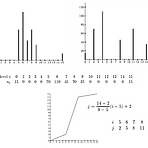
[Ch5] Pointing Processing
5.1 Introduction Image processing operation - Transforming the grey values of the pixels - Divided into 3 classes based on the information required to perform transformation 1) Transforms - Need : Knowledge of all the grey levels in the entire image to transform the image 2) Spatial filters - Need : Value of the grey levels in a small neighborhood of pixels around the given pixel - To change the..
 [DE] 크롤링
[DE] 크롤링
1. 기본 개념 1) 크롤링 : 웹 페이지를 그대로 가져와서 거기서 필요한 데이터(정보)를 추출하는 작업 2) Request & Response HTTP : 웹 상에서 클라이언트와 서버 간에 요청 & 응답으로 데이터를 주고 받을 수 있는 프로토콜 Methods : 클라이언트가 서버로 보내는 요청(Request) 방법 9개의 요청 방법 중 주로 GET, POST 방식 사용 (1) GET : 클라이언트가 서버에게 조회할 리소스를 요청. 요청 값을 URL에 담아 *쿼리스트링을 통해 전송 * 쿼리스트링 : URL 끝에 붙은 '?' 뒤의 key-value 쌍을 이루는 요청 파라미터 Ex) https://URL?name=mike&age=20 : name이 mike, age가 20일 때의 응답을 보내줘! (2) PO..
 [DS] RNN
[DS] RNN
1. AI/ML/DL 개요 1) 포함 관계 및 정의 2) DL 분야 (1) Dataset (데이터셋) - Training Data - Validation Data - Test Data (2) CV (컴퓨터비전) - Image Classification - Object Detection - Image Segmentation - Saliency Detection (특정 인식) (3) NLP (자연어처리) - Text Classification & Ranking (텍스트 분류 및 순위) - Sentiment Analysis (감성 분석) - Doc Summarization (문서 요약) - Name-Entity Recognition, NER (개체 이름 인식) - Speech Recognition (음성 인식..
 [Ch10] 생성적 적대 신경망(GAN)
[Ch10] 생성적 적대 신경망(GAN)
더보기 1) 확률분포 : 확률 변수가 특정한 값을 가질 확률을 나타내는 함수 (1) 이산확률분포 : 확률변수 X의 개수를 정확히 셀 수 있을 때 (Discrete 값) (2) 연속확률분포 : 확률변수 X의 개수를 정확히 셀 수 없을 때 (Continuous 값) - 확률밀도함수로 표현 (Ex) 정규분포(Normal distribution) - 실제 세계의 많은 데이터는 정규분포로 표현 가능 2) 이미지 데이터에 대한 확률분포 : 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포 (다변수 확률분포) - 이미지 데이터는 다차원 특징 공간의 한 점으로 표현됨 → 이미지의 분포를 근사하는 모델 학습 가능 - 사람 얼굴에는 통계적인 평균치가 존재 → 모델은 이를 수치적으로 표현 가능 3) 생성 모델 (G..
 [Ch9] 오토인코더(AE)
[Ch9] 오토인코더(AE)
더보기 1) 확률분포 : 확률 변수가 특정한 값을 가질 확률을 나타내는 함수 (1) 이산확률분포 : 확률변수 X의 개수를 정확히 셀 수 있을 때 (Discrete 값) (2) 연속확률분포 : 확률변수 X의 개수를 정확히 셀 수 없을 때 (Continuous 값) - 확률밀도함수로 표현 (Ex) 정규분포(Normal distribution) - 실제 세계의 많은 데이터는 정규분포로 표현 가능 2) 이미지 데이터에 대한 확률분포 : 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포 (다변수 확률분포) - 이미지 데이터는 다차원 특징 공간의 한 점으로 표현됨 → 이미지의 분포를 근사하는 모델 학습 가능 - 사람 얼굴에는 통계적인 평균치가 존재 → 모델은 이를 수치적으로 표현 가능 9.1 AE 소개 및..