
티스토리 뷰
1) 확률분포
: 확률 변수가 특정한 값을 가질 확률을 나타내는 함수
(1) 이산확률분포
: 확률변수 X의 개수를 정확히 셀 수 있을 때 (Discrete 값)
(2) 연속확률분포
: 확률변수 X의 개수를 정확히 셀 수 없을 때 (Continuous 값)
- 확률밀도함수로 표현 (Ex) 정규분포(Normal distribution)
- 실제 세계의 많은 데이터는 정규분포로 표현 가능
2) 이미지 데이터에 대한 확률분포
: 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 분포 (다변수 확률분포)
- 이미지 데이터는 다차원 특징 공간의 한 점으로 표현됨 → 이미지의 분포를 근사하는 모델 학습 가능
- 사람 얼굴에는 통계적인 평균치가 존재 → 모델은 이를 수치적으로 표현 가능
3) 생성 모델 (Generative model)
: 실존하지 않지만 있을 법한 데이터(이미지, 음성, 텍스트 등)를 생성하는 모델
- 목표 : 이미지 데이터의 분포를 근사하는 모델 G를 만드는 것
(모델 G가 잘 동작한다 = 원래 이미지들의 분포를 잘 모델링할 수 있다)
- 학습 : 각각의 클래스에 대해 적절한 확률분포를 학습
- 결과 : 확률값 높은 부분에 대한 데이터를 Sampling 하면 다양한 있을 법한 데이터 생성 가능
- 모델 예시 : GAN, VAE, ...
10.1 GAN 소개 및 학습 원리
📄Generative Adversarial Nets (GAN) / 2014
📝 https://github.com/jeonggg119/DL_paper/issues/19
1) GAN
(1) Generative(생성적) : 데이터 자체를 생성
- 대표적인 생성 모델 : GAN, VAE(Variational AutoEncoder)
(2) Adversarial(적대적) : 생성자(G)와 구분자(D) 두 개의 네트워크를 활용한 모델
- 생성자와 구분자 간의 상반되는 목적 함수(Objective function)를 통해 학습
- 학습 이후, 생성자를 주로 사용 (구분자는 생성자의 학습을 도와주는 용도)
(3) Network(신경망) : 생성자와 구분자의 구조가 인공신경망 형태 (NN or CNN)
2) GAN 구조

(1) Generator(생성자)

: 랜덤 노이즈 벡터 z를 입력 받아 신경망을 통해 Fake 데이터를 생성
- 랜덤 노이즈 벡터는 표준정규분포(N(0,1))를 따르는 데이터면 충분
- z 벡터의 길이는 생성하는 데이터 종류마다 다르지만 MNIST는 50 정도면 충분
- 신경망(NN or CNN)의 은닉층 개수, 합성곱 필터 size 등은 Hyperparameter
- 목표 : Fake 데이터가 1(Real)에 가깝게 나오도록 생성하는 것
(생성 모델의 분포가 원본 데이터의 분포를 근사할 수 있도록 학습)

- 결과 : G가 학습이 잘 되었다면 원본 데이터의 확률분포를 근사할 수 있으므로, 확률값 높은 부분에 대한 데이터를 Sampling 하여 통계적으로 평균적인 특징을 가지는 다양한 데이터 쉽게 생성 가능
(2) Discriminator(구분자)

: Real 데이터와 Fake 데이터를 입력 받아 각각의 Real 유무에 대한 수치값(float) 출력
- 목표 : Real 데이터는 1에, Fake 데이터는 0에 가깝게 나오도록 학습
3) Objective function (목적 함수)
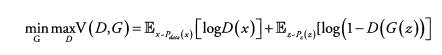
G : 생성자
D : 구분자
x : 데이터
z : 랜덤 노이즈
E : 기댓값(평균값) - 코드상에서는 모든 데이터를 하나씩 뽑아 식에 대입한 뒤 평균 계산
기댓값 공식
기댓값은 모든 사건에 대해 확률을 곱하면서 더하여 계산 가능
X : 확률변수, x : 사건, f(x) : 확률 분포 함수 (확률값)
- 이산확률변수에 대한 기댓값
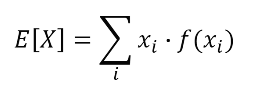
- 연속확률변수에 대한 기댓값
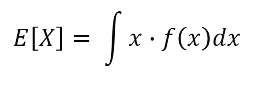
x ~ P_data(x) : 원본 data의 분포에서 한 개의 데이터 x를 Sampling (하나의 이미지를 뽑는 것)
D(x) : 위에서 뽑은 Real 데이터를 D에 넣은 결과 = 얼마나 Real 같은지 대한 probability (Real : 1, Fake : 0)
z ~ P_z(z) : 노이즈 분포에서 랜덤하게 하나의 노이즈 z를 Sampling (하나의 노이즈를 뽑는 것)
G(z) : 생성된 Fake 데이터 (new data instance)
D(G(z)) : 생성된 Fake 데이터를 D에 넣은 결과 = 얼마나 Real 같은지 대한 probability (Real 1 ~ Fake 0)
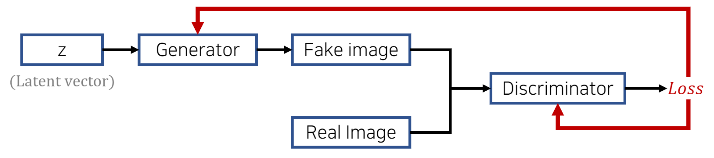
(1) Discriminator 입장 : max_D
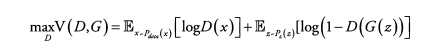
logD(x)와 log(1-D(G(z)))를 maximize 하려면 ? D(x) = 1, D(G(z)) = 0
→ Real 데이터 x가 D를 통과했을 때 1, 생성된 Fake 데이터 G(z)가 D를 통과했을 때 0으로 판단하도록 학습
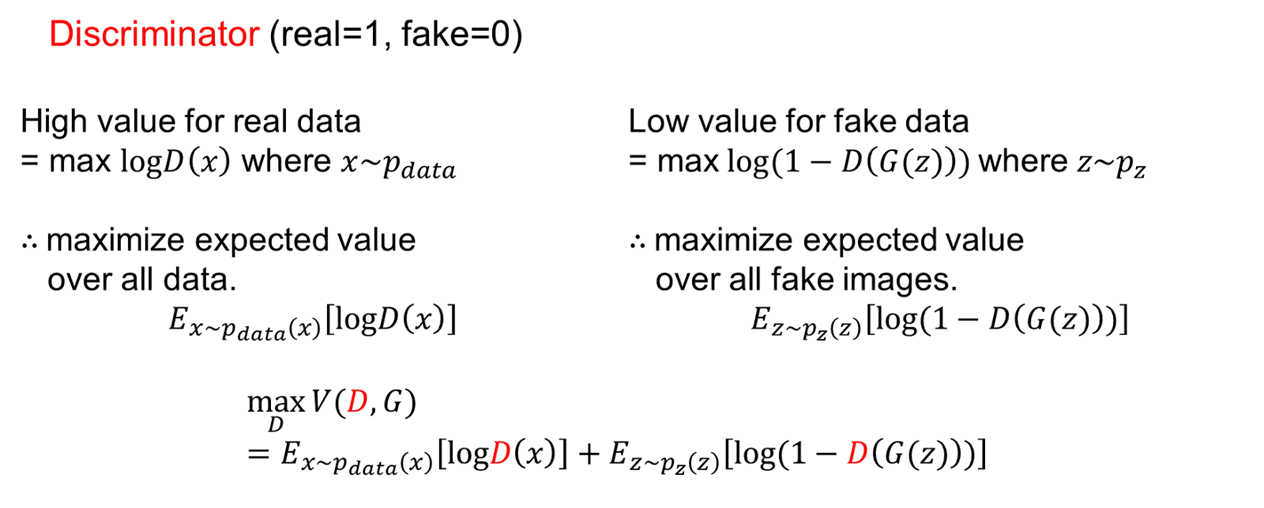
(2) Generator 입장 : min_G
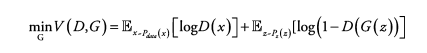
log(1-D(G(z)))를 minimize 하려면 ? D(G(z)) = 1
→ 생성한 Fake 데이터 G(z)가 D를 통과했을 때 1로 판단되도록 학습

(3) 목표
D가 Objective function을 달성한 최적의 상태일 때, G가 Objective function을 달성하는 것
= 생성된 Fake 데이터의 분포 P_g(x)가 Real 데이터의 분포 P_data(x)와 같아지게 만드는 것
= 학습이 다 잘 이루어진 후에는 D가 Real과 Fake를 구분할 수 없으므로 D(G(z)) = 1/2

= D가 최적의 상태일 때, G의 Objective function은 두 분포의 Jensen-Shannon divergence를 최소화하는 것
Global optimum point : P_g(x) = P_data(x)
[ Proof ]


10.2 모델 구현 및 학습
1) Loss function
Need : Loss를 정의하고 최소화하는 방식으로 모델 학습 + GAN의 Objective function 달성
(1) Discriminator Loss function

Discriminator의 Objective function을 Loss function 형태로 변경해야 함
→ max_D를 min_D로 바꾸기 위해 Real 데이터가 들어오는 경우의 term에 (-) 붙임

= CE Loss 형태와 같아짐 + 카테고리 2개 (Real/Fake)
= BCE Loss (Real 데이터에 대한 라벨 1 & Fake 데이터에 대한 라벨 0) 사용
D(x) = 1, D(G(z)) = 0
dis_loss = torch.sum(loss_func(dis_fake,zeros_label))
+ torch.sum(loss_func(dis_real,ones_label))
(2) Generator Loss function
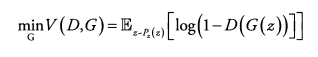
노이즈 z를 받아서 Fake 데이터를 생성하고, 이것이 Real로 구분되도록 함
→ min_G를 max_G로 바꿔 log(D(G(z))) term을 학습하는 것이 더 유리
초기 학습 빠르게 진행 가능 (Gradient 고려했을 때, 더 높은 Gradient 가질 수 있음)

= CE Loss 형태와 같아짐 + 카테고리 2개 (Real/Fake)
= BCE Loss (Fake 데이터에 대해 라벨 1) 사용
D(G(z)) = 1
gen_loss = torch.sum(loss_func(dis_fake,ones_label)) # fake classified as real(3) Algorithm of training GAN


2) GAN Model
(1) Generator class
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.layer1 = nn.Sequential(OrderedDict([
('fc1',nn.Linear(z_size,middle_size)),
('bn1',nn.BatchNorm1d(middle_size)),
('act1',nn.ReLU()),
]))
self.layer2 = nn.Sequential(OrderedDict([
('fc2', nn.Linear(middle_size,784)),
('bn2', nn.BatchNorm1d(784)),
('tanh', nn.Tanh()),
]))
def forward(self,z):
out = self.layer1(z)
out = self.layer2(out)
out = out.view(batch_size,1,28,28)
return out- self.layer1(z) : Linear 함수로 (batch_size,50)의 랜덤 노이즈 벡터 z를 입력 받아
- self.layer2(out) : Linear 함수로 MNIST size인 784로 늘리고, tanh(-1~1) 통과
- out.view(batch_size,1,28,28) : MNIST 이미지 형태(1,28,28)로 변경해 출력
∴ Fake MNIST 데이터 생성
(2) Discriminator class
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.layer1 = nn.Sequential(OrderedDict([
('fc1',nn.Linear(784,middle_size)),
('bn1',nn.BatchNorm1d(middle_size)),
('act1',nn.LeakyReLU()),
]))
self.layer2 = nn.Sequential(OrderedDict([
('fc2', nn.Linear(middle_size,1)),
('bn2', nn.BatchNorm1d(1)),
('act2', nn.Sigmoid()),
]))
def forward(self,x):
out = x.view(batch_size, -1)
out = self.layer1(out)
out = self.layer2(out)
return out- MNIST 형태(1,28,28) 데이터 x를 입력 받아
- x.view(batch_size,-1) : NN에 통과시키기 위해 쭉 784 size 벡터 형태로 펴준 후
- self.layer1(out) : 몇 개의 layers를 통과시키고
- self.layer2(out) : 마지막 layer로 Sigmoid(0~1)를 통과시켜 확률값으로 출력
∴ 입력받은 데이터가 Real인지 Fake인지에 대해 판단한 수치 값 float(0~1) 출력
(3) Networks & Loss function & Optimizer
# Put instances on Multi-gpu
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
generator = nn.DataParallel(Generator()).to(device)
discriminator = nn.DataParallel(Discriminator()).to(device)
# Loss function & Optimizer
loss_func = nn.MSELoss() # BCELoss보다 L2 Loss가 더 안정적 (LSGAN)
gen_optim = torch.optim.Adam(generator.parameters(), lr=0.0002,betas=(0.5,0.999))
dis_optim = torch.optim.Adam(discriminator.parameters(), lr=0.0002,betas=(0.5,0.999))
# Label
ones_label = torch.ones(batch_size,1).to(device)
zeros_label = torch.zeros(batch_size,1).to(device)- nn.DataParallel : Multi-GPU에 올릴 수 있음 (Default = 사용 가능한 모든 GPU)
- GAN에서는 BCELoss 사용했지만, LSGAN 등에서 사용한 L2 Loss (MSELoss) 쓰면 더 안정적 학습 가능
- Generator와 Discriminator를 번갈아 가며 각각 따로 학습 ← 각각 따로 Optim.Adam 지정
- torch.ones와 torch.zeros로 Loss 계산할 때 필요한 라벨 미리 생성
(4) Train
for i in range(epoch):
for j,(image,label) in enumerate(train_loader):
image = image.to(device)
# Discriminator 학습
dis_optim.zero_grad()
# Fake Data
# 랜덤 노이즈 z를 Sampling
z = init.normal_(torch.Tensor(batch_size,z_size),mean=0,std=0.1).to(device)
gen_fake = generator.forward(z)
dis_fake = discriminator.forward(gen_fake)
# Real Data
dis_real = discriminator.forward(image)
# 두 Loss 더해 최종 Loss에 대해 기울기 계산
dis_loss = torch.sum(loss_func(dis_fake,zeros_label)) + torch.sum(loss_func(dis_real,ones_label))
dis_loss.backward(retain_graph=True)
dis_optim.step()
# Generator 학습
gen_optim.zero_grad()
# Fake Data
# 랜덤 노이즈 z를 Sampling
z = init.normal_(torch.Tensor(batch_size,z_size),mean=0,std=0.1).to(device)
gen_fake = generator.forward(z)
dis_fake = discriminator.forward(gen_fake)
# 최종 Loss에 대해 기울기 계산
gen_loss = torch.sum(loss_func(dis_fake,ones_label)) # fake classified as real
gen_loss.backward()
gen_optim.step()
# model save
if j % 100 == 0:
print(gen_loss,dis_loss)
torch.save([generator,discriminator],'./model/vanilla_gan.pkl')
v_utils.save_image(gen_fake.cpu().data[0:25],"./result/gen_{}_{}.png".format(i,j), nrow=5)
print("{}th epoch gen_loss: {} dis_loss: {}".format(i,gen_loss.data,dis_loss.data))# Discriminator(D) Train
- z = init.normal_() : 랜덤 노이즈 z를 Sampling
- gen_fake = generator.forward(z) : Sampling한 z를 G에 전달해 Fake 데이터 생성
- dis_fake = discriminator.forward(gen_fake) : Fake 데이터를 D에 넣어 나온 값
- dis_real = discriminator.forward(image) : Real 데이터를 D에 입력해 나온 값
- loss_func(dis_fake, zeros_label) : Fake 데이터를 D에 넣어 나온 값과 0 라벨을 이용해 Loss 계산
- loss_func(dis_real, ones_label) : Real 데이터를 D에 입력해 나온 값과 1 라벨을 이용해 Loss 계산
- dis_loss = torch.sum(loss_func(dis_fake, zeros_label)) + torch.sum(loss_func(dis_real, ones_label)),
dis_loss.backward(), dis_optim.step() : 모든 데이터에 대해 두 Loss를 더하여 최종 Loss를 구해 모델 update
# Generator(G) Train
- z = init.normal_() : 랜덤 노이즈 z를 Sampling
- gen_fake = generator.forward(z) : Sampling한 z를 G에 전달해 Fake 데이터 생성
- dis_fake = discriminator.forward(gen_fake) : Fake 데이터를 D에 넣어 나온 값
- gen_loss = torch.sum(loss_func(dis_fake, ones_label)) :Fake 데이터를 D에 넣어 나온 값과 1 라벨을 이용해 Loss 계산
- gen_loss.backward(), gen_optim.step() : 모든 데이터에 대해 Loss 값 이용해 모델 update
(5) Result
from glob import glob
for i in range(epoch):
print(i)
file_list = glob("./result/gen_{}_*.png".format(i))
img_per_epoch = len(file_list)
for idx,j in enumerate(file_list):
img = plt.imread(j)
plt.subplot(1,img_per_epoch,idx+1)
plt.imshow(img)
plt.show()
- Result 별로 좋지 X → G와 D의 구조가 단순하기 때문 (Linear)
- Linear 대신 Conv 쓰고 모델의 layer 수를 늘리면 결과 향상될 것
+) GAN 논문에서의 결과
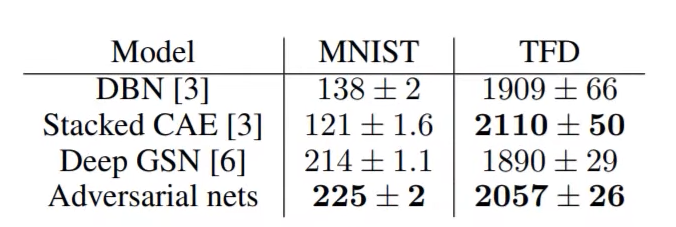

10.3 유명한 모델들과 원리
1) DCGAN (Deep Convolutional GAN)
(1) DCGAN = GAN + Convolution
DCGAN : 모델이 어떤 의미를 가지는 특성(표현)을 학습해 생성해내는 Network
(2) 구조
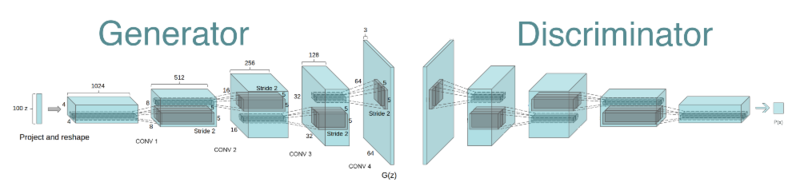

Generator
: Trans-Conv 통해 랜덤 노이즈 z로부터 이미지 데이터 생성
# Generator receives random noise z and create 1x28x28 image
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(100,7*7*256),
nn.BatchNorm1d(7*7*256),
nn.ReLU(),
)
self.layer2 = nn.Sequential(OrderedDict([
('conv1', nn.ConvTranspose2d(256,128,kernel_size=4,stride=2,padding=1)), # (B,128,14,14)
('bn1', nn.BatchNorm2d(128)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(128,64,kernel_size=3,stride=1,padding=1)), # (B,64,14,14)
('bn2', nn.BatchNorm2d(64)),
('relu2', nn.ReLU()),
]))
self.layer3 = nn.Sequential(OrderedDict([
('conv3',nn.ConvTranspose2d(64,16,kernel_size=4,stride=2,padding=1)), # (B,16,28,28)
('bn3',nn.BatchNorm2d(16)),
('relu3',nn.ReLU()),
('conv4',nn.Conv2d(16,1,kernel_size=3,stride=1,padding=1)), # (B,1,28,28)
('relu4',nn.Tanh())
]))
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
elif isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
def forward(self,z):
out = self.layer1(z)
out = out.view(batch_size,256,7,7)
out = self.layer2(out)
out = self.layer3(out)
return out
Discriminator
: Conv 통해 이미지 입력 받아 Real / Fake 구분해 수치(0~1) 출력
# Discriminator receives 1x28x28 image and returns a float number 0~1
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.layer1 = nn.Sequential(OrderedDict([
('conv1',nn.Conv2d(1,8,kernel_size=3,stride=1,padding=1)), # (B,8,28,28)
('bn1',nn.BatchNorm2d(8)),
('relu1',nn.LeakyReLU()),
('conv2',nn.Conv2d(8,16,kernel_size=3,stride=2,padding=1)), # (B,16,14,14)
('bn2',nn.BatchNorm2d(16)),
('relu2',nn.LeakyReLU()),
]))
self.layer2 = nn.Sequential(OrderedDict([
('conv3',nn.Conv2d(16,32,kernel_size=3,stride=1,padding=1)), # (B,32,14,14)
('bn3',nn.BatchNorm2d(32)),
('relu3',nn.LeakyReLU()),
('conv4',nn.Conv2d(32,64,kernel_size=3,stride=2,padding=1)), # (B,64,7,7)
('bn4',nn.BatchNorm2d(64)),
('relu4',nn.LeakyReLU())
]))
self.fc = nn.Sequential(
nn.Linear(64*7*7,1),
nn.Sigmoid()
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
elif isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
def forward(self,x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(batch_size, -1)
out = self.fc(out)
return out
(3) 학습 성능 향상 방안
- Pooling을 Convolution 연산으로 대체
- G는 Trans-Conv 연산 사용
- G와 D에 Batch-normalization 사용
- FC layer 사용 X
- G의 모든 Activation func으로 ReLU (마지막에 사용되는 tanh 제외)
- D의 모든 Activation func으로 LeakyReLU
(4) Train
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
generator = nn.DataParallel(Generator()).to(device)
discriminator = nn.DataParallel(Discriminator()).to(device)
loss_func = nn.MSELoss()
gen_optim = torch.optim.Adam(generator.parameters(), lr=learning_rate,betas=(0.5,0.999))
dis_optim = torch.optim.Adam(discriminator.parameters(), lr=learning_rate,betas=(0.5,0.999))
ones_label = torch.ones(batch_size,1).to(device)
zeros_label = torch.zeros(batch_size,1).to(device)
# Train
for i in range(epoch):
for j,(image,label) in enumerate(train_loader):
image = image.to(device)
# generator
gen_optim.zero_grad()
z = init.normal_(torch.Tensor(batch_size,100),mean=0,std=0.1).to(device)
gen_fake = generator.forward(z)
dis_fake = discriminator.forward(gen_fake)
gen_loss = torch.sum(loss_func(dis_fake,ones_label)) # fake classified as real
gen_loss.backward()
gen_optim.step()
# discriminator
dis_optim.zero_grad()
z = init.normal_(torch.Tensor(batch_size,100),mean=0,std=0.1).to(device)
gen_fake = generator.forward(z)
dis_fake = discriminator.forward(gen_fake)
dis_real = discriminator.forward(image)
dis_loss = torch.sum(loss_func(dis_fake,zeros_label)) + torch.sum(loss_func(dis_real,ones_label))
dis_loss.backward()
dis_optim.step()
# model save
if j % 1000 == 0:
torch.save([generator,discriminator],'./model/dcgan.pkl')
print("{}th iteration gen_loss: {} dis_loss: {}".format(i,gen_loss.data,dis_loss.data))
v_utils.save_image(gen_fake.cpu().data[0:25],"./result/gen_{}_{}.png".format(i,j), nrow=5)
(5) Result
from glob import glob
for i in range(0,epoch,5):
print(i)
file_list = glob("./result/gen_{}_*.png".format(i))
print(file_list)
img_per_epoch = len(file_list)
plt.figure(figsize=(25,5))
for idx,j in enumerate(file_list):
img = plt.imread(j)
plt.subplot(1,img_per_epoch,idx+1)
plt.imshow(img)
plt.show()

- 결과 : 이전 GAN에 비해 이미지 생성 결과 뛰어남 (에폭 거듭할수록 좋은 결과)
- Noteworthy : 모델이 데이터를 외운 것이 X, 어떤 특성을 학습했다는 점
(4) Latent space interpolation (잠재 공간 보간)
: Latent vector z의 공간을 탐색하는 방식

- 방법 : 길이 100 vector z에서 다른 값들을 고정하고 하나의 값만 연속적으로 바꿔보며 결과 변화 관찰
- 결과 : z에서 한 요소의 값이 변함에 따라 생성되는 이미지가 부드럽게 변함
- 해석 : 창문이 없던 방에서 창문이 생성됨 -> z에서 해당 부분이 창문의 유무, 크기에 대한 특성 학습
(5) Vector 간 연산

자연어 처리 word2vec 모델(모든 단어를 일정 길이의 vector로 변환. vector 간 연산 가능)
이미지 처리 DCGAN 모델에서도 Vector 간 연산 가능 (비지도 학습으로 가능)
2) SRGAN (Super-Resolution GAN)
(1) SRGAN


SRGAN : *Super Resolution 작업에 GAN을 적용한 Network
Loss = MSE + 생성된 이미지가 Real 고화질 영상인지 SR을 거친 영상인지 구분하는 GAN Loss
→ 고화질 영상의 특성인 '선명함'이 이미지 생성에 영향을 줌
Loss function : I^SR = I_x^SR + 10^(-3)*I^SR_Gen
- I^SR : Perceptual Loss (for VGG based content losses) = Content loss + Adversarial loss
- I_x^SR : Content loss = pixel-wise MSE loss + 0.006*VGG loss
- I^SR_Gen : Adversarial loss(GAN loss)
* Super Resolution : 저화질의 이미지를 입력으로 받아 고화질로 변환하는 작업
- 세부적인 형태에 대한 정보가 사라진 상태이므로 이에 대한 다양한 경우의 수 존재
- MSE로만 학습하면 다양한 경우에 대해 가장 Loss를 작게 하는 '평균'적인 영상 생성하므로 흐릿 부분 존재
- GAN은 D를 속이기 위해 여러 가능한 고화질 영상 중에서도 '특정'한 경우를 생성 ; Mode collapse

(2) Mode Collapse (모드 붕괴)
: G가 D를 속일 수 있는 '특정' 데이터만 생성해내는 현상
Ex) MNIST 데이터의 경우 어떤 z가 들어와도 G가 0만 생성
- 다양한 생성물을 원하는 경우에는 단점으로 작용
- Super Resolution 작업 시에는 Real 같은 특정 이미지를 생성하는데 좋음
(3) Oscillation (진동)
: 학습이 이뤄지는 동안 다양한 경우를 왔다 갔다 하며 여러 결과를 생성하는 현상(생성된 결과 계속 변함)
Ex) MNIST 데이터의 경우 어떤 z가 들어와도 특정 시점에는 0만 만들다가 이후 다른 시점에는 6을 만들고 나중에는 4도 만드는 등 왔다 갔다 하며 여러 결과를 생성
- cGAN 처럼 추가 조건을 부여하면 완화 가능
3) cGAN(conditional GAN)
: 실제 데이터 라벨을 *조건(condition)으로 G와 D에 전달하여 해당 라벨의 데이터 생성
= 데이터의 모드(mode)를 제어할 수 있도록 조건(condition) 정보를 함께 입력
*조건(condition) Ex. class label, text description, image, ...


+) InfoGAN
: condition에 해당되는 라벨도 알아서 찾도록 유도하는 GAN
4) Text-conditional convolutional GAN

: 텍스트를 조건으로 받아 이미지를 생성하는 cGAN
- 특정 문장 vector + 랜덤 노이즈 vector를 G에 입력해 Real 이미지 생성
- 생성된 이미지 + 특정 문장 vector를 조건(Condition)으로 함께 D에 입력
→ 특정 문장을 조건으로 Fake 이미지를 생성
- 같은 문장을 조건으로 생성된 Fake 이미지 VS Real 이미지 구분하는 cGAN 모델
- Real 이미지와 그 이미지를 묘사하는 텍스트도 D에 전달되어 Real 데이터의 분포 학습
Image-to-Image (I2I) Translation
: The task to change a particular aspect of a given img to another
Ex) Pix2Pix, CycleGAN, DiscoGAN, StarGAN, ...
[Keywords]
attribute : meaningful feature inherent in an img (ex. hair color, gender, age)
attribute value : a particulat value of an attribute (ex. black/brown/blond for hair color, male/female for gender)
domain : a set of imgs sharing the same attribute value
5) Pix2Pix
(1) Pix2Pix
: 이미지를 조건(condition)으로 받아 이미지를 생성하는 cGAN
- G : 이미지 x를 조건으로 입력 받아 이미지 G(x) 생성
- D : x와 G(x)를 쌍으로 입력 받아 두 이미지가 진짜 쌍인지 구분
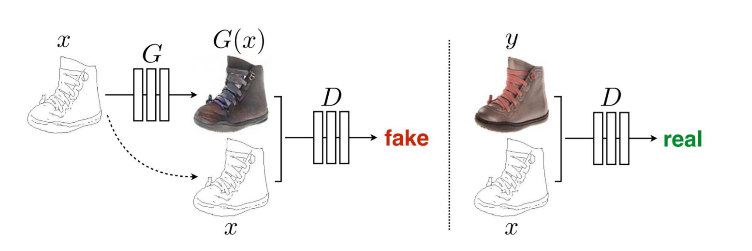
(2) Pix2Pix의 한계점
- 서로 다른 두 도메인 X, Y의 데이터를 한 쌍(Paired)으로 묶어 학습 진행 → Unpaired Dataset에 대해서는 적용 hard
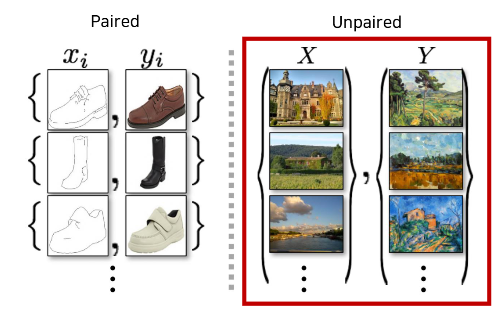
6) CycleGAN
(1) CycleGAN
: Pix2Pix 방식의 단점(x와 G(x)의 실제 쌍 데이터가 필요)을 극복한 모델

(2) 문제 상황
- 별도의 제약 조건 없이 단순히 입력 이미지 x의 일부 특성을 타겟 도메인 Y의 특성으로 바꾸고자 한다면 어떤 입력이든 특정한 도메인에 해당되는 하나의 이미지만 제시하게 될 수도 있음 (Discriminator 입장에선 있을 법한 이미지 + 특정 클래스로 분류)

(3) 목적 및 작동 원리
▪ 목적
: G(x)가 다시 원본 이미지 x로 재구성(reconstruct)될 수 있는 형태로 만들어지도록 함
→ 원본 이미지의 Content는 보존(preserve)하고 도메인과 관련된 특징만 바꿈

▪ 동작 원리
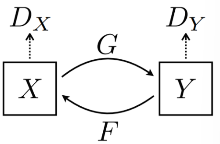
① 2개의 변환기(translator) [ G : X → Y ] & [ F : Y → X ]
② Cycle-consistency loss → F(G(x)) ~~ x & G(F(y)) ~~ y
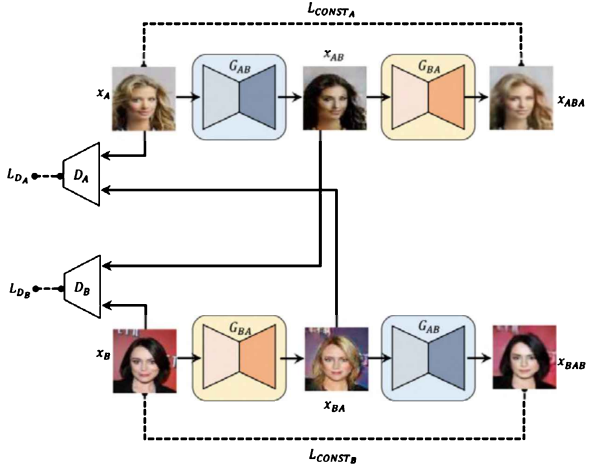
7) DiscoGAN
① 변환하고자 하는 데이터셋 준비 (금발 사진, 흑발 사진)
주의점 : 변환하고자 하는 특징이 아닌 다른 조건들은 최대한 일정하게 유지
(이미지 간의 변환이 비지도학습으로 이뤄지므로 인물 수 등 다른 요소가 개입되면 학습 잘 X)
② 학습 진행 (도메인 A에서 B로의 변환 & 도메인 B에서 A로의 변환)
각 도메인에서 변환된 생성 이미지들은 일반적인 GAN 모델처럼 D에 들어가 Real/Fake 구분
+ 이미지 형태를 잡아주기 위한 *Reconstruction Loss function
*Reconstruction Loss function
= 원본 이미지와 A에서 B로 변환된 이미지를 다시 A 도메인으로 복원했을 때 생성된 복원 이미지의 절댓값 차이
→ A에서 B로 변환할 때 다시 원본 이미지로 돌아갈 수 있도록 원본 형태를 보존 + B 도메인의 특성만 변환
8) WGAN-GP
함수가 1-Lipshichtz 조건을 만족하도록 하여 안정적인 학습 유도함
- WGAN : weight clipping 이용해 제약 조건을 만족하도록 함- WGAN-GP : Gradient penalty 이용해 WGAN의 성능을 개선

9) StarGAN
📄 StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation / 2017
(1) 등장 배경
▪ Cross-domain models : 기존 I2I 구조를 그대로 이용한다면 여러개의 네트워크가 필요
▪ StarGAN : 하나의 NN model 만 이용해 다중 도메인(Multi-domain) 사이에서의 이미지 변환(I2I Translation) 가능
→ parameter 측면에서도 공간 효율적, 다양한 도메인에서 사용되는 데이터셋을 함께 활용(공통적 feature 학습) 가능
Facial attribute transfer(CelebA), Facial expression synthesis(RaFD) tasks 에서 사용
CelebA dataset : 40 labels related to facial attributes (ex. hair color, gender, age)
RaFD dataset : 8 labels for facial expressions (ex. happy, angry, sad)

(2) 동작 원리
Inputs : Img & Domain information(condition)
Training : randomly generate a Target domain label and train model to translate an input img into target domain
Testing : control domain label and translate img into any desired domain

(a) Training Discriminator
- cGAN 구조를 따름
- Real/Fake 구분하도록 학습 +Real img 입력된 경우엔 Domain classification도 진행
(b) Original-to-target domain
(c) Target-to-original domain
- (b), (c) 에서는 Cycle-consistency loss 이용
- 원본 Content (Identity)는 보존하고 도메인과 관련된 특징만 바꿈
(d) Fooling Discriminator
- Generator가 만든 Fake img가 Real distribution 따르도록 만듦
(3) Loss function

x : input img
y : output img
c : target domain label
G(x,c) → y
D : x → { D_src(x), D_cls(x) }
D_src(x) : x가 Real/Fake 구분
D_cls(x) : x가 Real인 경우 어떤 class(targer domain)인지
① Adversarial loss : L_adv
D는 Maximize, G는 Minimize L_adv
→ 있을 법한 이미지를 만들 수 있도록 구성
② Domain classification loss : L_cls^r, L_cls^f
D가 보조적인 classifier를 이용 → Real img인 경우 class 구할 수 있음
L_cls^r : D를 위한 loss (real img가 들어왔을 때 class를 맞추도록 학습)
L_cls^f : G를 위한 loss (fake img가 의도했던 target domain c로 분류될 수 있도록 D를 속임)
③ Reconstruction loss
G가 Cycle consistency loss 이용 → 원본이미지의 content (identity) 유지
∴ 특정 class로 보이는 있을 법한, 그럴싸한 이미지를 만들 수 있도록 구성 + 원본이미지의 content (identity) 유지
(4) Mask Vector

- Multiple dataset 에서의 학습을 위해 Mask vector m 사용할 수 있음 (Label을 Concat)
- Model can focus on the label provided by a paricular dataset
- JNT : 더 많은 데이터를 활용하면 더 높은 성능낼 수 있는 가능성 ↑

(5) Training with Multiple Datasets
- 한꺼번에 여러 개의 Attributes 를 변경할 수 있음 (Multiple domain)
- Network Architecture : CycleGAN + PatchGANs 기반

(6) Results



9) Progressive Growing of GANs (PGGAN = ProGAN)
▪ Main Idea
- 학습 진행 과정에서 점진적으로(progrssively) network의 layer를 추가하는 방식
- 고해상도 이미지 학습 성공

▪ 한계점
- Blackbox
- 이미지의 특징(feature) 제어 어려움 → StyleGAN 에서 개선
10) StyleGAN
📄 A Style-Based Generator Architecture for Generative Adversarial Networks / CVPR 2019
StyleGAN : 여러 개의 style 을 조합한 하나의 고화질 이미지 생성
- Generator에 초점을 맞춰 연구 (D는 거의 그대로)
- Unsupervised Separation of high-level attributes (ex. pose and identity)
- Stochastic Variation in generated imgs (ex. freckles, hair) BY Noise = 매번 바뀔 수 있는 확률적인 다양성
- Intuitive and scale-specific control of synthesis
- PGGAN baseline Architecture 보다 성능 향상
- Better Interpolation properties
- Better Disentanglement (여러 feature들이 서로 얽혀있지 않도록 하는 특성 = More Linear) → 다양한 특징들 분리 가능
- Disentanglement 관련 성능 측정 지표 제안
- 1024 x 1024 고해상도 얼굴 데이터셋 (FFHQ) 발표

(1) StyleGAN 구성 요소
▪ Mapping Network ( f : z → w )
- 512 차원의 z-domain에서 w-domain으로의 mapping 수행 (Learned mapping f : z → w)
- (b) Z space : Fixed distribution → Gaussian Distribution에서 sampling 한 z vector를 직접 사용 X
- (c) W space : factors of variation become more Linear ! → 계산된 w vector를 사용하는 것이 좋음 (Disentangled)


▪ Adaptive Instance Normalization (ADalN)
- AdlN 이용하면 다른 원하는 데이터로부터 스타일(style) 정보를 가져와 적용 가능
(학습시킬 parameter X, feed-forward 방식의 style transfer network에서 좋은 성능)


▪ Removing Traditional Input
- Network의 초기 입력 : Noise Latent vector 가 아닌 learned Constant Tensor(4 x 4 x 512) → 경험적 성능 향상

▪ Stochastic Variation
- Noise를 입력에 추가함으로써 확률적인 측면의 다양성 (ex. 머리카락의 배치, 주근깨) 컨트롤



Style : high-level global attributes (ex. 얼굴형, 포즈, 안경 유무 등)
Noise : stochastic variations (ex. 주근깨, 피부 모공 등)
- Coarse Noise (Front layer) : 큰 크기의 머리 곱슬거림, 배경 등
- Fine Noise (Rear layer) : 세밀한 머리 곱슬거림, 배경 등
(a) : 모든 layer에 Noise 적용
(b) : Noise 적용 X
(c) : Fine (Rear) layer에 적용
(d) : Coarse (Front) layer에 적용
(2) Architecture : Disentanglement Properties
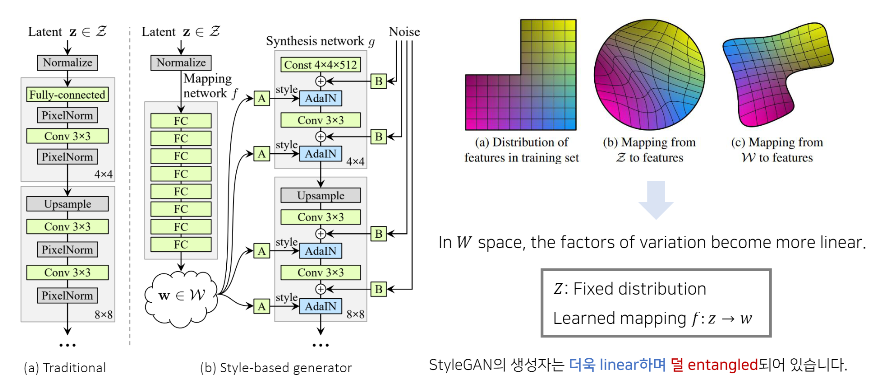
① Latent z(512차원)를 뽑은 뒤 하나의 Mapping network(8 layers)를 거쳐 w vector(512차원)로 바꿈
② 각각의 block마다 w vector를 2번씩 별도의 Affine transformation 거쳐 style 정보 얻은 뒤 AdaIN에 입력 (scaling, bias)
- 각각의 block 거칠수록 너비, 높이는 2배로 증가 (총 9개) 하므로 18x512차원이 Generator(18 layers)에 입력됨
③ 각각의 block마다 convolution 연산 이후에 Noise도 2번씩 들어감
- Noise size는 Feature map size와 비례하여 증가시킴
즉, 저해상도 초기 입력 Fixed Constant(4x4x512) x에서 시작해
각각의 block마다 w style vector와 Noise가 각각 2개씩 입력되며
점점 C는 감소하고 H,W는 증가하며
최종적으로는 1024x1024 RGB 고화질 이미지 생성
(3) Latent Vector Meanings

- Coarse styles : 포즈, 얼굴형, 안경 유무 등 큼지막한 정보
- Middle styles : 중간 정보
- Fine styles : 머리색, 배경색 등 작은 정보
(4) Evaluation : FID (Frechet Inception Distance) 값 비교/분석

A : PGGAN Baseline model
B : Tuning (Bilinear up/downsampling operations, hyperparams tuning, longer training)
C : Mapping Network + AdaIN
D : Inpur layer로 학습된 4x4x512 Constant Tensor 사용
E : Noise Input 추가
F : Mixing Regularization
두 dataset에 대하여 모두 점점 성능 올라감
(5) Style Mixing (Mixing Regularization)
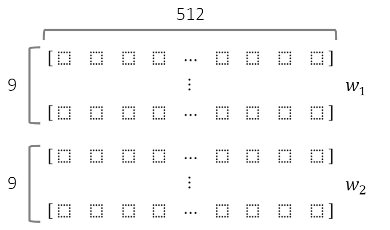

- 인접한 layer 간의 Style Correlation (상관관계) 줄임
- 각 layer에 대하여 Styles to Localize (지역화)
- Mixing Regularization 구체적인 방법
① 2개의 입력 벡터(Latent vector) w1, w2 준비
② Crossover 포인트 설정
③ Crossover 이전은 w1, 이후는 w2 사용
* Style Mixing ≠ Interpolation
(6) Disentanglement 관련 성능 측정 지표 제안
① Path Length
: 2개의 Latent vectors를 보간(Interpolation)할 때 얼마나 급격하게 이미지 특징이 바뀌는지 평가
- Latent Vector Interpolation methods : LERP(Linear Interpolation), SLERP(Spherical Linear Interpolation)
- Perceptual Path Length : 지점 t 와 t+ε 사이에서의 VGG 특징(features)의 거리가 얼마나 먼지 계산

② Linearity Separability
: Latent space 에서 Attributes가 얼마나 선형적(Linear)으로 분류될 수 있는지 평가
▪ CelebA-HQ : 얼굴마다 성별(gender) 등의 40개의 binary attributes가 명시된 dataset
▪ 각 속성(Attribute)마다 200,000개의 이미지를 생성해 40개 분류(Classification)하는 보조 network에 입력
→ Confidence가 낮은 절반을 제거해 100,000개의 label이 명시된 Latent vector 생성
→ 이 100,000개의 데이터를 training dataset으로 사용
▪ 매 Attribute마다 Linear SVM model을 학습 (Traditional GAN에서는 z를, StyleGAN에서는 w를 이용)
→ 각 Linear SVM model을 이용해 다음의 엔트로피 값을 계산 ( i = 각 Attribute의 index )
(엔트로피가 낮을수록 더 Linear하게 분류가 잘 되는 것)
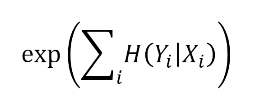
(7) Additional Experiment Results
- 동일한 setting으로 LSUN Bedroom dataset, LSUN Car dataset에 대해 추가 실험 진행
- Coarse styles (카메라 구도) / Middle styles (특정 가구) / Fine styles (세밀한 색상, 재질 등) 변화

11) StyleGAN2
📄Analyzing and Improving the Image Quality of StyleGAN / CVPR 2020
'DL > Pytorch' 카테고리의 다른 글
| [Ch9] 오토인코더(AE) (0) | 2022.01.31 |
|---|---|
| [Ch8] Neural Style Transfer (0) | 2022.01.24 |
| [Ch7] 학습 시 생길 수 있는 문제점 및 해결방안 (0) | 2022.01.22 |
| [Ch6] 순환신경망(RNN) (0) | 2022.01.20 |
| [Ch5] 합성곱 신경망(CNN) (0) | 2022.01.15 |